»Prvič, sem političarka in ne politik, drugič pa …«Korpusni pristop k raziskovanju parlamentarnega diskurza
IZVLEČEK
1V tem učnem gradivu predstavljamo uporabnost jezikovnih korpusov za analizo družbenokulturnih pojavov, ki jih lahko raziskujemo na podlagi jezikovne rabe v specializiranem, političnem diskurzu. Na primeru korpusne analize govorov poslank in poslancev, kjer nas bo zanimala dinamika zastopanosti žensk v parlamentu in značilnosti njihove rabe jezika, bomo pokazali vrednost bogato označenega diahronega korpusa slovenskih parlamentarnih razprav za digitalno humanistiko in družboslovje.
2Ključne besede: parlamentarne razprave, parlamentarni korpusi, jezik in spol, digitalna humanistika
ABSTRACT
"FIRST, I’M A FEMALE POLITICIAN, NOT A MALE ONE, AND SECOND …”
A CORPUS APPROACH TO PARLIAMENTARY DISCOURSE RESEARCH
1This tutorial shows how corpora can be used to investigate language use and communication practices in a specialized socio-cultural context of political discourse in order to explore socio-cultural phenomena. We will demonstrate the potential of a richly annotated diachronic corpus of Slovenian parliamentary debates for investigating the characteristics and dynamics of the representation of women and their language use in the Slovenian Parliament.
2Keywords: Parliamentary proceedings, parliamentary corpora, language and gender, digital humanities
1. Uvod1
1V parlamentu se odvija glavnina političnih razprav, na podlagi katerih se oblikuje zakonodaja, ki nato neposredno vpliva na vsakdanje življenje vseh prebivalcev in prebivalk določene države. V parlamentarnem diskurzu se tudi odsevajo politični programi, ideološka stališča in institucionalne vloge poslank in poslancev, ki zastopajo interese državljanov in državljank.2 Zato je parlamentarni govor vedno aktualen predmet družboslovnih in humanističnih raziskav.
2Zapisi parlamentarnih sej so vse pogosteje dostopni v digitalni obliki, kar poenostavlja njihovo združevanje v strukturirane jezikovne vire oziroma korpuse. Ti so pogosto na voljo prek namenskih spletnih orodij, ki jih imenujemo konkordančniki. Raziskovalci jih uporabljajo pri različnih jezikovnih, slogovnih, kulturnih, družbenih in političnih raziskavah.3
3Medtem ko so v jezikoslovju metode korpusne analize že dodobra uveljavljene4 in se med drugim pogosto uporabljajo tudi za sociolingvistično proučevanje spolno zaznamovanega jezika,5 so v drugih humanističnih in družboslovnih vedah, kjer prav tako številne raziskave temeljijo na jezikovnem gradivu, še razmeroma redke. V tem učnem gradivu zato prikazujemo potencial bogato označenih jezikovnih korpusov in konkordančnikov za raziskave družbenokulturnih pojavov, ki se odražajo v rabi jezika. Za oblikovanje natančnih kvantitativnih poizvedb o jezikovnih podatkih uporabimo dragocene metapodatke o poslankah in poslancih in njihovih govorih, rezultate pa nato še nadgradimo z ročno kvalitativno analizo, s katero pridobimo podroben vpogled v kontekst in zagotovimo ustrezno interpretacijo.
4S tem učnim gradivom želimo prikazati možnosti, ki jih raziskovalkam in raziskovalcem brez programerskih znanj ponujajo obsežne zbirke parlamentarnih razprav in konkordančniki. To učno gradivo je primerno tudi za uporabnice in uporabnike brez izkušenj z uporabo jezikovnih korpusov in orodij za iskanje po njih. Gradivo temelji na korpusu siParl 2.0,6 ki vsebuje parlamentarne razprave Državnega zbora Republike Slovenije od leta 1990 do 2018.
2. Kako uporabljati učno gradivo
1V tem gradivu najprej predstavimo osnove korpusnega jezikoslovja in korpusne analize, čemur sledi uvod v značilnosti specializiranih korpusov parlamentarnih razprav in jedrnat pregled raziskav s področja jezika in spola. Drugi del učnega gradiva je namenjen praktičnemu prikazu najbolj razširjenih tehnik korpusne analize, kot so konkordančni nizi, frekvenčni seznami, ključne besede in kolokacije. Predstavljene tehnike uporabimo za raziskovanje zastopanosti žensk v slovenskem parlamentu, njihovih interesnih področij in govora o ženskah, pri čemer v analizo vključimo primerjavo z značilnostmi, ki veljajo za poslance oziroma skozi čas.
2Vsi viri in orodja, uporabljeni v tem gradivu, so brezplačno na voljo v spletu. Za iskanje po korpusu uporabljamo NoSketch Engine,7 za dodatne ročne analize in predstavitve rezultatov pa enega od urejevalnikov preglednic (npr. Google Spreadsheet 8 ali MS Excel 9).
3Besedila v modrih okvirčkih vsebujejo razlago uporabljenih funkcij in povezavo do videoposnetka, ki prikazuje, kako relevantno funkcijo poženemo v konkordančniku. Poleg tega so v okvirčkih tudi povezave do rezultatov v konkordančniku, kar bralkam in bralcem omogoča, da ponovijo analizo na svojem računalniku.
4Iskanje po korpusu siParl 2.0 je mogoče prek konkordančnikov NoSketch Engine 10 in KonText 11 na spletnem mestu CLARIN.SI 12 – slovenski center v okviru Evropske raziskovalne infrastrukture za jezikovne vire in tehnologije CLARIN ERIC.13 Prek repozitorija CLARIN.SI je korpus siParl 2.0 mogoče tudi prenesti 14 v računalnik in ga nato analizirati z drugimi korpusnimi orodji ali orodji za rudarjenje besedil, npr. z orodjem za korpusno analizo Antconc 15 ali z orodji za osnovno obdelavo besedil v jeziku R.16
5To gradivo je posodobljena različica izvirnega učnega gradiva,17 v katerem je bila uporabljena prva različica korpusa siParl. Korpus siParl 2.0 v primerjavi s korpusom siParl 1.0 18 vsebuje bogatejše metapodatke o govorkah in govorcih ter sejah, kar omogoča razlikovanje med poslankami in poslanci ter drugimi govorkami in govorci v parlamentu. Poleg tega govori vsebujejo oznake parlamentarnih mandatov, kar omogoča lažjo primerjalno analizo elementov med posameznimi parlamentarnimi sklici. Druga različica korpusa vsebuje tudi dodatne ravni jezikoslovnih oznak, kot so skladenjske oznake in imenske entitete, ki pa jih v naši analizi ne bomo uporabljali, zato jih v gradivu ne obravnavamo.
6Če želite tehnike korpusne analize takoj preizkusiti na praktičnih primerih, nadaljujte z nalogami v razdelku Korpusna analiza. Naslednji trije razdelki (Korpusi in konkordančniki, Zapisi parlamentarnih sej in Jezik in spol) so namreč namenjeni poljudnemu pregledu teoretičnih osnov in najpomembnejše terminologije. Čeprav nalogam v šestem razdelku lahko sledite brez predhodnega branja omenjenih treh razdelkov, vas spodbujamo, da se z njihovo vsebino na neki točki seznanite, saj predstavljene osnove zagotavljajo celovito razumevanje in samostojno rabo analitičnih postopkov ter ustrezno interpretacijo rezultatov.
3. Korpusi in konkordančniki
3.1. Korpusi
1Besedilni korpusi 19 so obsežne zbirke skrbno izbranih strojno berljivih jezikovnih podatkov, ki jih lahko uporabimo za pripravo jezikovnih opisov ali za preverjanje hipotez o jeziku. Vendar pa so korpusi veliko več kot le zbirke besedil v elektronski obliki. Oblikovani so v enem od standardnih formatov, kot je razširljivi označevalni jezik oziroma XML,20 in kodirani v skladu z vnaprej določeno, a prilagodljivo shemo za predstavitev besedil v digitalni obliki, med katerimi je v jezikoslovju in digitalni humanistiki najbolj uveljavljen standard TEI.21
2Osnovna enota korpusa je pojavnica,22 ki jo dobimo z avtomatskim postopkom tokenizacije, pri katerem je izbrano besedilo razdeljeno na manjše enote, v našem primeru na besede. Običajno se pojavnice določajo glede na presledke med besedami. Za bolj poglobljeno analizo so besedila v korpusu jezikoslovno označena. Najosnovnejši obliki jezikoslovnega označevanja sta oblikoskladenjsko označevanje, s katerim besedam v besedilih pripišemo besedno vrsto (npr. glagol), in lematizacija,23 pri kateri pojavnicam (besednim oblikam v različnih sklonih) pripišemo osnovno slovarsko obliko oz. lemo. Lematizacija je pomembna zlasti za korpuse morfološko bogatih jezikov, kot je slovenščina. Poleg jezikoslovnih oznak so v korpus dodani tudi metapodatki o besedilu (npr. datum, vrsta) in govorcu (npr. ime, spol), ki so pomembni za kontekstualizacijo rezultatov, vendar se lahko uporabljajo tudi za izvajanje natančnejših korpusnih poizvedb.
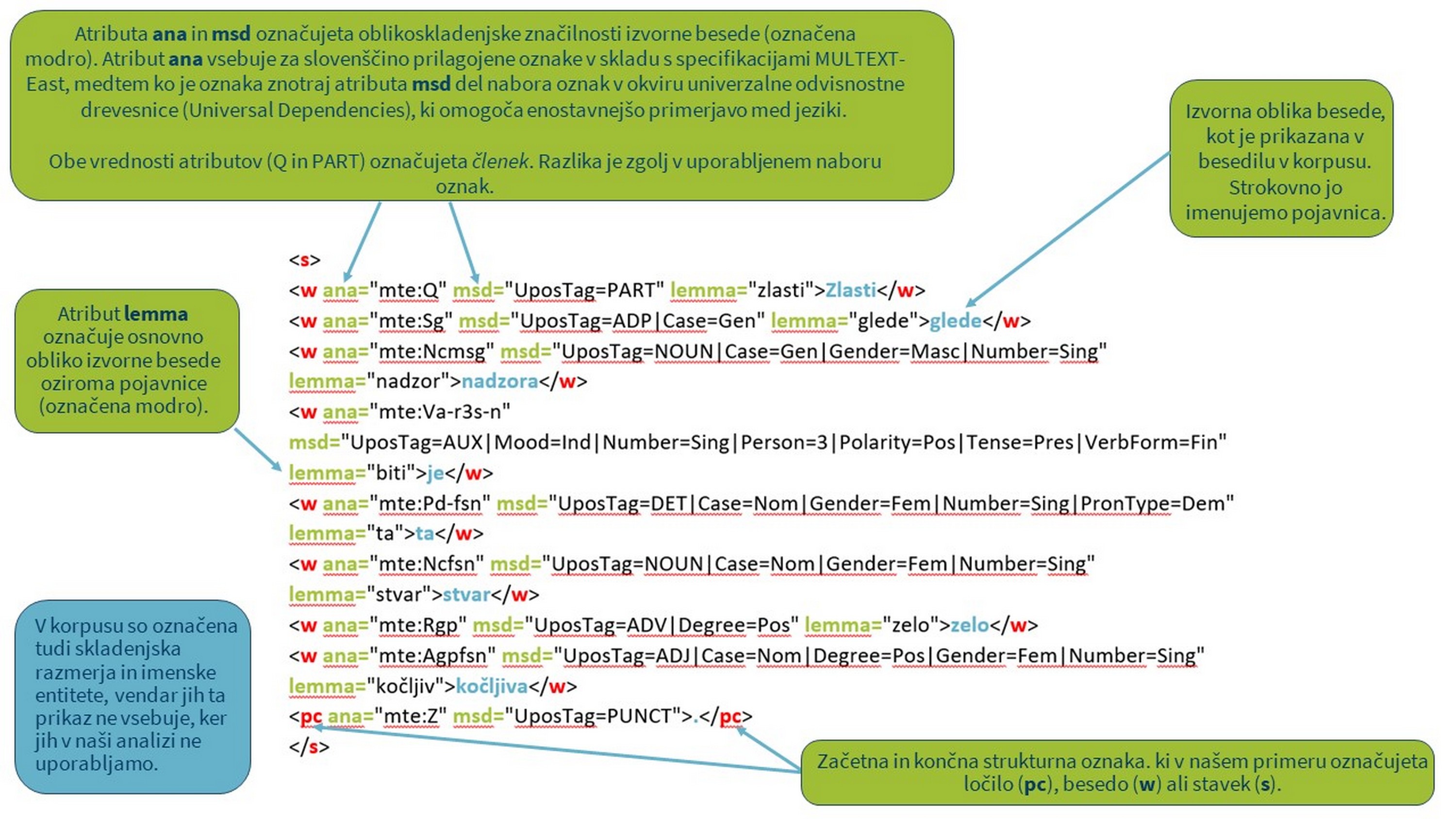
3.2. Konkordančniki
1Po korpusih iščemo s specializiranimi orodji, ki se imenujejo konkordančniki.24 Nekatere konkordančnike moramo pred uporabo namestiti na osebni računalnik, drugi pa so dostopni neposredno prek spleta. Uporabljamo jih za iskanje vseh pojavitev pojavnic v korpusu, ki ustrezajo našemu iskalnemu pogoju. Na voljo je veliko konkordančnikov, ki omogočajo podobne funkcije (gl. npr. ta podrobn i seznam),25 med najbolj priljubljenimi pa so AntConc 26 (brezplačen) in WordSmith Tools 27 (potreben je nakup licence), ki ju je mogoče uporabljati brez internetne povezave in ne vsebujeta predhodno naloženih korpusov, ter spletna konkordančnika BYU 28 (za polno delovanje je potrebna brezplačna registracija) in SketchEngine 29 (brezplačna akademska licenca), ki vsebujeta številne predhodno naložene korpuse za različne jezike. SketchEngine omogoča tudi ustvarjanje in označevanje lastnih korpusov.
2Večina sodobnih konkordančnikov omogoča naslednje funkcije, ki jih bomo uporabili tudi v tem gradivu:
- Konkordančni niz 30 prikazuje vse zadetke iskane besede ali niza besed v korpusu ter njihovo sobesedilo. Konkordance, posamezne enote konkordančnega niza, so lahko razvrščene naključno ali glede na iskano besedo oziroma niz besed. Razvrstiti jih je mogoče tudi glede na levi ali desni kontekst, kar izpostavi značilne vzorce, v katerih se iskana beseda oziroma niz besed pojavlja.
- Frekvenčni seznami 31 prikazujejo vse zadetke za izbrano korpusno poizvedbo, ki je lahko v obliki besede/besedne zveze ali določenega nabora metapodatkov. Zadetki so lahko razvrščeni po abecedi ali pogostosti, pripisan pa jim je tudi podatek o njihovi frekvenci. V nasprotju s konkordančnim nizom besedni seznami ne vsebujejo sobesedila zadetkov.
- Seznami ključnih besed 32 izpostavljajo besede, ki v izbranem korpusu izstopajo v primerjavi z izbranim referenčnim korpusom.
- Seznami kolokacij 33 vsebujejo nize besed, ki se v kombinaciji z iskano besedo pojavljajo pogosteje kot ob naključnem pojavljanju.
3Na voljo so že številna navodila za uporabo konkordančnikov (npr. SketchEngine Quick Start Guide 34) in tečaji korpusnega jezikoslovja (npr. Corpus Linguistics : Method , Analysis , Interpretation 35 ). V tem gradivu se osredotočamo na prikaz uporabe konkordančnika NoSketchEngine in specializiranega korpusa za iskanje odgovorov na konkretna raziskovalna vprašanja na metodološko ustrezen način. Gradivo je namenjeno študentkam in študentom ter raziskovalkam in raziskovalcem s področja (digitalne) humanistike in družboslovja, ki jih zanima raziskovanje sociokulturnih pojavov prek jezikovne rabe.
4. Zapisi parlamentarnih sej
1Parlamentarni korpusi so različnih velikosti in vsebujejo podatke v različnih modalitetah (pisni, govorjeni, gestikulacija), iz različnih časovnih obdobij in v enem ali več jezikih. Čeprav so parlamentarne razprave večinoma dostopne v pisni obliki (npr. korpus razprav iz danskega parlamenta 36), so včasih dostopne tudi kot zvočni posnetki ali videoposnetki skupaj s transkripcijami (npr. korpus razprav iz češkega parlamenta 37). Parlamentarni korpusi kot diahroni viri38 nam omogočajo poglobljeno raziskovanje jezikovnih in družbenih sprememb skozi čas. Večina parlamentarnih korpusov vsebuje bogate metapodatke 39 o govorih (npr. datum govora, trajanje govora, točka dnevnega reda, v kateri je bil govor podan) ali govorkah in govorcih (npr. spol, starost, izobrazba, politična pripadnost, institucionalna vloga), kar omogoča poglobljen vpogled v kontekst preučevanega pojava.40
4.1. Parlamentarni diskurz
1Parlament je institucija, za katero veljajo specifična pravila in konvencije, kar vpliva tudi na jezikovno rabo, začenši s pravili glede podeljevanja besede, naslavljanja itd. (gl. npr. poslovnik državnega zbora RS 41). Ta pravila in konvencije so se izoblikovale v določenem družbenozgodovinskem okolju, zato niso v vseh parlamentih enake; v grškem parlamentu je na primer skakanje v besedo strogo prepovedano, medtem ko je v britanskem parlamentu prekinjanje govorcev pogosto in običajno ni sankcionirano.42 To je seveda treba upoštevati pri oblikovanju raziskovalnih vprašanj, izvedbi raziskave in interpretaciji rezultatov. Zato je pri raziskovanju te vrste diskurza43še posebej pomembno, da dobro razumemo okoliščine, v katerih je nastal.
4.2. Zanesljivost sejnih zapisov
1Uradno objavljeni sejni zapisi niso dobesedne transkripcije 44 parlamentarnih razprav, ampak zapisi v skladu z uveljavljenimi zapisovalnimi praksami institucije. Te prakse se razlikujejo med posameznimi državami in časovnimi obdobji. Med urejanjem zapisov običajno pride do izločanja značilnih prvin govorjenega jezika, lahko pa tudi do nekaterih drugih posegov, kot so izločanje očitnih jezikovnih ali vsebinskih napak, narečnih ali pogovornih izrazov ter žaljivega in vulgarnega jezika. Smernice za urejanje sejnih zapisov običajno žal niso javno objavljene, kar lahko bistveno oteži raziskovalno delo. Kritiko virov v parlamentarnem kontekstu podrobneje obravnavata Mollin45 in Rix.46 Drug pomemben vidik pri proučevanju parlamentarnega govora je, da so govori poslank in poslancev pogosto pripravljeni vnaprej, in sicer v pisni obliki, kar vpliva na njihove skladenjske in slogovne značilnosti. To sicer ne velja za vsa parlamentarna okolja, niti za vse vrste parlamentarnih nastopov (npr. interpelacije, obrazložitve glasu, poslanska vprašanja). Tudi te posebnosti je poleg družbenozgodovinskega konteksta treba vedno upoštevati pri oblikovanju raziskovalnih vprašanj, izvedbi raziskave in interpretaciji rezultatov.
2Slika 2 prikazuje primerjavo uradnega zapisa govora Anje Bah Žibert,47 poslanke Državnega zbora RS 2014–2018, s 33. seje Državnega zbora na temo predloga zakona o Prešernovi nagradi (18. točka dnevnega reda48) z dobesedno transkripcijo njenega govora, ki smo jo pripravili na podlagi videoposnetka seje (min. 5:00–7:33).49 Že na prvi pogled se vidi, da uradni sejni zapisi DZ RS niso najboljši vir za preučevanje značilnosti spontanega govora, kot so napačni začetki, premori, raba mašil ali ponovitev.

4.3. Poznavanje raziskovalnih podatkov
1Predpogoj za ustrezno oblikovanje raziskovalnih vprašanj, izvedbo raziskave in interpretacijo rezultatov, pa tudi za optimalno izkoriščanje vsega, kar raziskovalni podatki omogočajo, je, da se najprej podrobno seznanimo s tem, kaj izbrani korpus vsebuje, kako je bil zgrajen in označen ter kakšne so njegove omejitve. Ker niso vsi korpusi enako označeni, moramo vedno preveriti podrobnosti o izbranem korpusu. Te informacije so običajno na voljo na domači strani korpusa (npr. korpus historične nizke nemščine 50), v konkordančniku, prek katerega je korpus na voljo (npr. britanski parlamentarni korpus Hansard v konkordančniku Univerze Brigham Young 51), ali v repozitoriju, kjer je korpus arhiviran (npr. hrvaški parlamentarni korpus ParlaMeter-hr v repozitoriju CLARIN.SI 52). Več o kodiranju in označevanju parlamentarnih podatkov lahko preberete v izobraževalnem modulu o zbirkah parlamentarnih podatkov PARTHENOS . 53
5. Jezik in spol
1Razlike med jezikom moških in žensk so predmet številnih raziskav na področju sociolingvistike, stilistike, retorike, študij spola, medijskih študij in analize diskurza.54 Rezultati kažejo, da so razlike majhne, a sistematične.55 Pri raziskavah politične komunikacije pa lahko opazimo, da se tradicionalno posvečajo predvsem diskurzu politikov, medtem ko je diskurz političark šele pred kratkim postal predmet raziskav.56
2To je pomembno, ker je več avtoric57 pokazalo, da se zakonodajalke razlikujejo od svojih sodelavcev pri vprašanjih, ki jih naslavljajo, stališčih, ki jih zavzemajo, in pristopih, ki jih uporabljajo pri pripravi zakonodaje. Blaxill in Beelen58 sta v analizi zastopanosti žensk v britanskem parlamentu po letu 1945 odkrila, da je v govorih poslank večji poudarek na vprašanjih, ki zadevajo ženske (npr. izobraževanje, zdravstvo itd.) in ki se neposredno dotikajo njihove dobrobiti v družbi (npr. varstvo otrok, nasilje v družini, enakost itd.).59 Tudi Bäck idr.,60 Hansen idr.61 ter Mensah in Wood,62 ki so raziskovali korpuse razprav iz švedskega, danskega oz. ganskega parlamenta, so odkrili, da ženske pogosteje kot moški govorijo o temah, ki se tičejo t. i. mehkih zakonodajnih področij (npr. makroekonomija, energetika, promet, bančništvo, finance, vesolje, znanost in tehnologija ter komunikacija63), medtem ko moški pogosteje razpravljajo o temah s t. i. trdih zakonodajnih področij (npr. zdravstvo, delo, zaposlitev in priseljevanje, izobraževanje ter socialno varstvo).
3Upoštevati je treba, da na uporabo jezika vplivajo različni dejavniki (npr. družbeni razred, kontekst, starost, hierarhija), pri čemer je spol le eden od mnogih.64 Bing in Bergvall65 poudarjata, da so podobnosti v uporabi jezika pri različnih spolih običajno spregledane, čeprav so bolj izrazite kot razlike. Tudi Blaxill in Beelen66 sta odkrila podobno težnjo v okviru raziskav parlamentarnega diskurza. Če torej spol govorca poznamo vnaprej, kot to velja v našem primeru, je treba to dejstvo nujno upoštevati, da se izognemo napačni interpretaciji rezultatov in pretiranemu poudarjanju razlik.67
6. Korpusna analiza
1V tem razdelku bomo na obsežnem korpusu slovenskih parlamentarnih razprav pokazali, kako lahko osnovne tehnike korpusne analize (za več o tem gl. razdelek 3 Korpusi in konkordančniki) uporabimo za iskanje odgovorov na naslednja raziskovalna vprašanja:
- V Nalogi 1 bomo analizirali zastopanost žensk v slovenskem parlamentu. Najprej si bomo ogledali, kako ustvarimo podkorpuse. Nato se bomo naučili, kako sestaviti frekvenčne sezname, ki prikazujejo število govorcev oziroma govork in njihovih govorov v podkorpusih.
- V Nalogi 2 bomo identificirali tematike, o katerih so skozi čas razpravljale poslanke v primerjavi s poslanci. Pri tem se bomo naučili, kako izluščimo ključne besede iz podkorpusov, in si nato ogledali, kako prek analize konkordanc preverimo njihov kontekst in rabo.
- V Nalogi 3 bomo raziskali, kako so poslanke in poslanci v minulih 25 letih razpravljali o tematikah, povezanih z ženskami. Ogledali si bomo, kako uporabljamo podatke o relativni frekvenci v različno velikih podkorpusih in kako izluščimo kolokacije izbranih samostalnikov v podkorpusih.
6.1. Korpus siParl 2.0
1Korpus siParl 2.0 68 vsebuje sejne zapise 11. mandata Skupščine socialistične republike Slovenije za obdobje 1990-1992, sejne zapise Državnega zbora Republike Slovenije69 za obdobje 1992-2018 (1.–7. mandat), sejne zapise delovnih teles Državnega zbora Republike Slovenije za obdobje 1996-2018 (2.–7. mandat) in sejne zapise Sveta predsednika Državnega zbora za obdobje 1996–2018 (2.–7. mandat).
2Korpus vsebuje metapodatke o govorkah in govorcih (npr. ime, spol, vloga, politična stranka), tipologijo parlamentarnih zasedanj (npr. redna seja, izredna seja itd.) ter strukturne in uredniške oznake (npr. zakonodajno obdobje, leto/naslov seje, imenske entitete). 70 Korpus je tudi oblikoskladenjsko označen in lematiziran. Poleg tega vsebuje nekatere druge jezikoslovne oznake (npr. oznake univerzalne odvisnostne drevesnice (Universal Dependencies) in skladenjsko razčlenjevanje), ki pa jih v tem gradivu ne uporabljamo. Korpus obsega več kot milijon govorov oziroma 200 milijonov besed, ki jih je prispevalo skoraj 8.500 različnih govork in govorcev (npr. poslanke in poslanci, članice in člani vlade, predstavnice in predstavniki ministrstev, strokovnih organizacij, nevladnih organizacij in interesnih skupin). Splošne informacije o korpusih in o zapisih parlamentarnih sej najdete v razdelku 3 Korpusi in konkordančniki in v razdelku 4 Zapisi parlamentarnih sej.
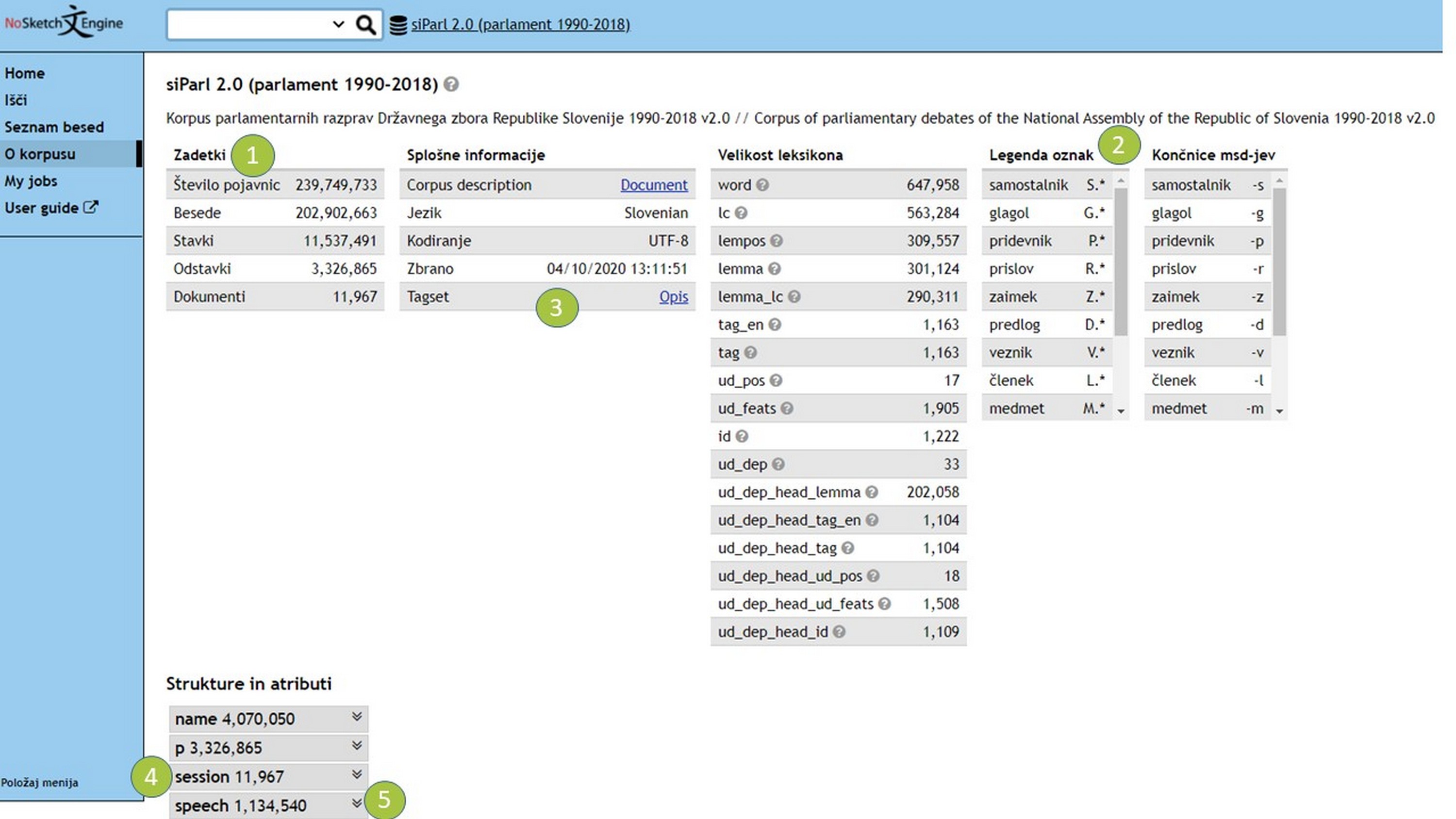
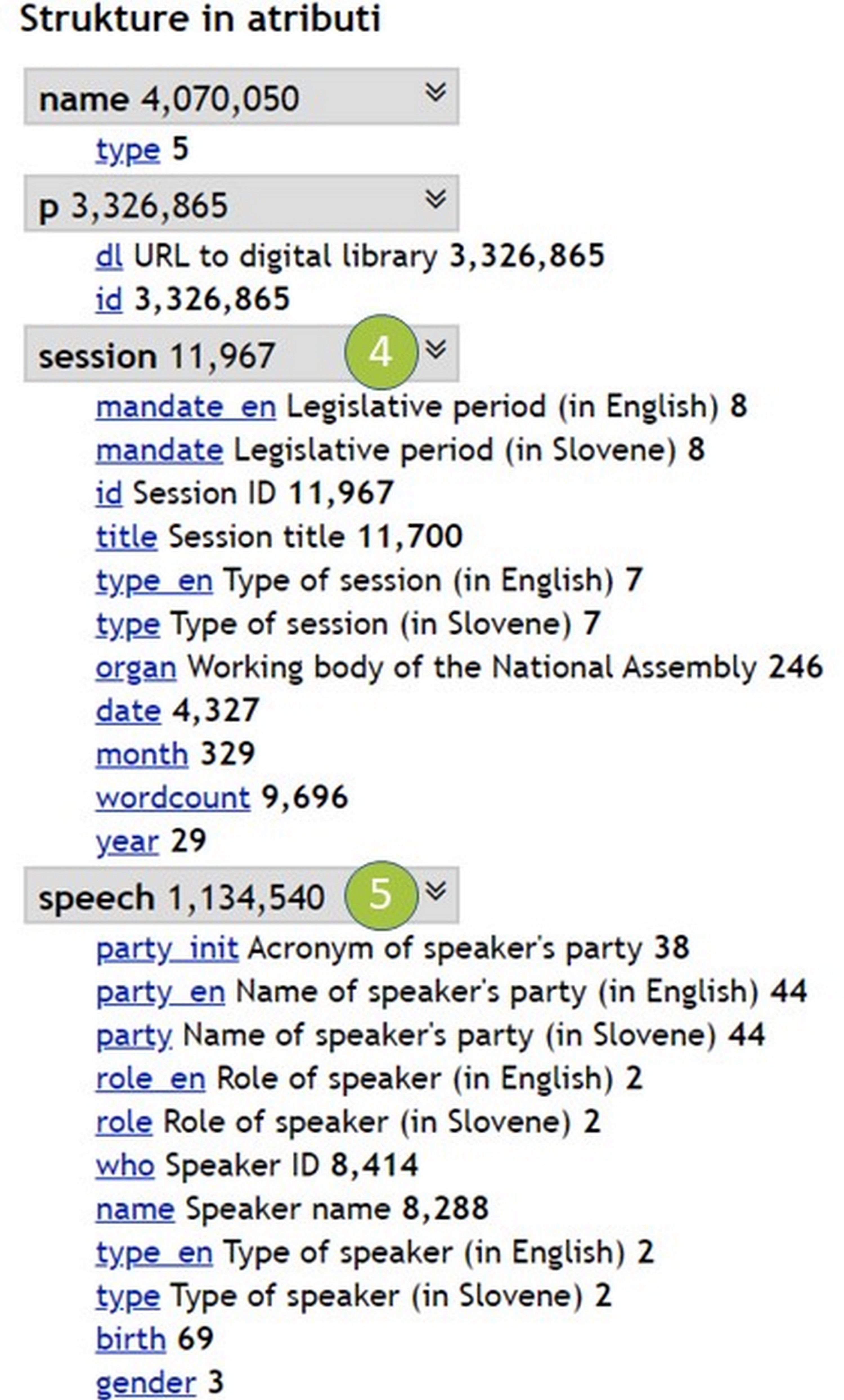
3Te informacije o korpusu so na voljo tudi v konkordančniku na strani CLARIN.SI 71 (gl. Sliki 3a in 3b):72
- Kvantitativne informacije o velikosti korpusa so na voljo v razdelku Zadetki (gl. številko 1).
- Osnovne oznake za besedne vrste so navedene v Legendi oznak (gl. številko 2), opis celotnega nabora oznak pa je na voljo prek povezave Tagset/Opis 73 (gl. številko 3).
- Korpus je organiziran prek strukturnih atributov. Atribut session/seja zamejuje posamezne seje (gl. številko 4) in vsebuje informacije, kot so datum, vrsta in naslov seje (gl. Sliko 3b, številko 4).
- Atribut speech/govor zamejuje posamezne govore (gl. številko 5) in vsebuje informacije o imenu, spolu, vlogi in strankarski pripadnosti govorke oz. govorca (gl. Sliko 3b, številko 5).
6.2. NALOGA 1: Zastopanost žensk v slovenskem parlamentu
1Državni zbor Republike Slovenije ima 90 poslank in poslancev, vključno s predstavnico oz. predstavnikom italijanske in madžarske manjšine, ki so trenutno del devetih političnih strank.74 Slovenija je ena od najmlajših držav Evropske unije, ki je v preteklih 30 letih doživela dramatične spremembe na področju enakosti spolov. Leta 1986, ko je bila Slovenija še vedno del Socialistične federativne republike Jugoslavije, so poslanke zasedale skoraj četrtino vseh poslanskih sedežev, leta 1992, ko je bil prvič sklican Državni zbor Republike Slovenija, pa se je ta delež občutno zmanjšal, saj so poslanke zasedale le še vsaki deseti poslanski sedež.75 Med postopkom tranzicije, ko so se družbeni, politični, gospodarski in vrednostni sistem bistveno spremenili, so ženske v Sloveniji izgubile več gospodarskih in družbenih prednosti, pridobljenih v času socializma, in so bile skoraj popolnoma izrinjene iz političnih institucij. V sedmem mandatu (1. 8. 2014–21. 6. 2018), ki je zadnji mandat, vključen v korpus siParl 2.0, so poslanke zasedle malo več kot 40 % sedežev, večinoma zaradi zakonodajnih ukrepov, ki predpisujejo spolne kvote.76 Glede na EU indeks vrednosti enakosti spolov in politične moči v Evropski uniji za leto 2017 77 je bila Slovenija uvrščena med prvih 10 držav Evropske unije po deležu poslank.
2V Nalogi 1 bomo primerjali govore v korpusu siParl 2.0 s trendi na parlamentarnih volitvah in v slovenski družbi.
6.2.1. Izdelava podkorpusov
1Na podlagi metapodatkov, ki so na voljo v korpusu (gl. Sliko 3b), korpus razdelimo na več delov, t. i. podkorpuse, in sicer glede na naslednja merila:
- Spol. Govorke in govorci so v korpusu označeni z eno od naslednjih kategorij v skladu s podatki iz uradnih sejnih zapisov državnega zbora: moški, ženska ali ni podatka (v primerih, ko so zapisi metapodatkov nepopolni). V tem gradivu uporabljamo le prvi dve kategoriji (moški, ženska), medtem ko tistih, za katere ni podatka o spolu, v analizo ne vključujemo.
- Vloga. Govorkam in govorcem je v korpusu pripisana ena od dveh vlog, in sicer član parlamenta oziroma zunanji govornik 78 (ta vloga označuje povabljene govorke in govorce, ki niso del parlamenta (npr. članice in člani vlade, predstavnice in predstavniki ministrstev ali nevladnih organizacij). V tem gradivu upoštevamo le govorce in govorke z oznako član parlamenta, ker se želimo osredotočiti na prispevke izvoljenih predstavnic in predstavnikov državljanov Slovenije.
- Tip. Poleg vloge je govorkam in govorcem v korpusu pripisan tudi njihov tip, ki ima eno od naslednjih dveh vrednosti: redni govornik alipredsedujoči. Prva kategorija označuje govorke in govorce v parlamentu, ki so v skladu s poslovnikom izrecno dobili besedo. V naši analizi upoštevamo le to kategorijo. Tiste z oznako predsedujoči smo namerno izključili, saj je večina njihovih izjav namreč pogojena s postopkovnimi predpisi in dogovori in torej nanje ne vplivajo strankarska pripadnost, spol ali drugi dejavniki.
- Mandat. Vsak govor v korpusu je kategoriziran glede na parlamentarno obdobje, v katerem je bil izrečen (1.–7. mandat). Ker to presega meje naše raziskave, smo iz analize izključili obdobje odcepitve od Jugoslavije,79 ki je v korpusu označeno kot 11. sklic.
- Delovni organ. Korpus siParl 2.0 vsebuje govore s plenarnih zasedanj, z zasedanj delovnih organov državnega zbora (npr. Komisija za peticije, človekove pravice in enake možnosti) in z zasedanj Sveta predsednika Državnega zbora. V tem gradivu analiziramo le govore s plenarnih zasedanj.
2Na podlagi teh meril izdelamo 14 podkorpusov, po dva za vsakega od sedmih mandatov, pri čemer eden vsebuje govore poslank, drugi pa govore poslancev s pripisano vlogo redni govornik. Poleg teh 14 podkorpusov izdelamo tudi podkorpuse, ki vsebujejo vse govore poslank in poslancev za vsak posamezni mandat in za vseh sedem mandatov skupaj.
3Videoposnetek, ki prikazuje izdelavo podkorpusa v konkordančniku NoSketch Engine, je na voljo na https://sidih.si/20.500.12325/120.
4Ustvarjeni podkorpusi in informacije o njihovi velikosti so na voljo tukaj.80
5Spodaj je naveden tudi primer zahtevnejšega iskalnega izraza v jeziku CQL, ki ga je treba uporabiti pri izdelavi spodnjega podkorpusa:
6Mandat1-Ženske: 81
7<speech gender="F" & role_en="MP" & type_en="Regular speaker"/> within <session mandate_en="Term 1 .*" & organ="Državni zbor Republike Slovenije"/>
8S tem ukazom poiščemo vse izjave (atribut speech/govor) govork (atributF/Ž), ki so članice parlamenta (atribut MP/Član parlamenta) in redne govorke (atribut Regular speaker/Redni govornik), in sicer v govorih iz prvega mandata (atribut Term 1 .*/1. Mandat .*), ki so bili izrečeni v Državnem zboru Republike Slovenije (atribut Državni zbor Republike Slovenije).
9Če želimo ustvariti podkorpus govorov poslancev, moramo spremeniti le spol prek atributa speech gender/spol (speech gender="M"). Za podkorpus, ki vsebuje govore poslank in poslancev iz vseh mandatov, pa moramo najprej vključiti moški in ženski spol prek atributa speech gender/spol (speech gender="F|M"), nato pa še vse mandate prek atributa session mandate/mandat seje (session mandate_en="Term .*").
6.2.2. Uporaba frekvenčnih seznamov
1V podkorpusih, ustvarjenih v prejšnjem koraku, bomo analizirali govore poslank in poslancev skozi čas, in sicer na podlagi podatkov s frekvenčnih seznamov,82 ki so ena od najosnovnejših korpusnih tehnik. Frekvenčni seznami prikazujejo rezultate od najbolj do najmanj pogostega. To tehniko lahko na primer uporabimo za sestavljanje frekvenčnega seznama vseh besed, ki so bile izrečene v parlamentu oziroma v govorih izbrane poslanke ali izbranega poslanca. V tej nalogi bomo s to tehniko pridobili podatke o številu vseh poslank in poslancev v posameznem mandatu ter številu njihovih govorov, vključno s skupnim številom pojavnic v teh govorih.
2Videoposnetek, ki prikazuje izdelavo frekvenčnega seznama v konkordančniku NoSketch Engine, je na voljo na https://youtu.be/LrYmwK51Fbc.
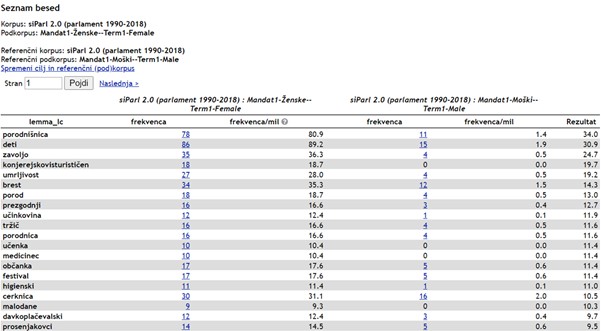
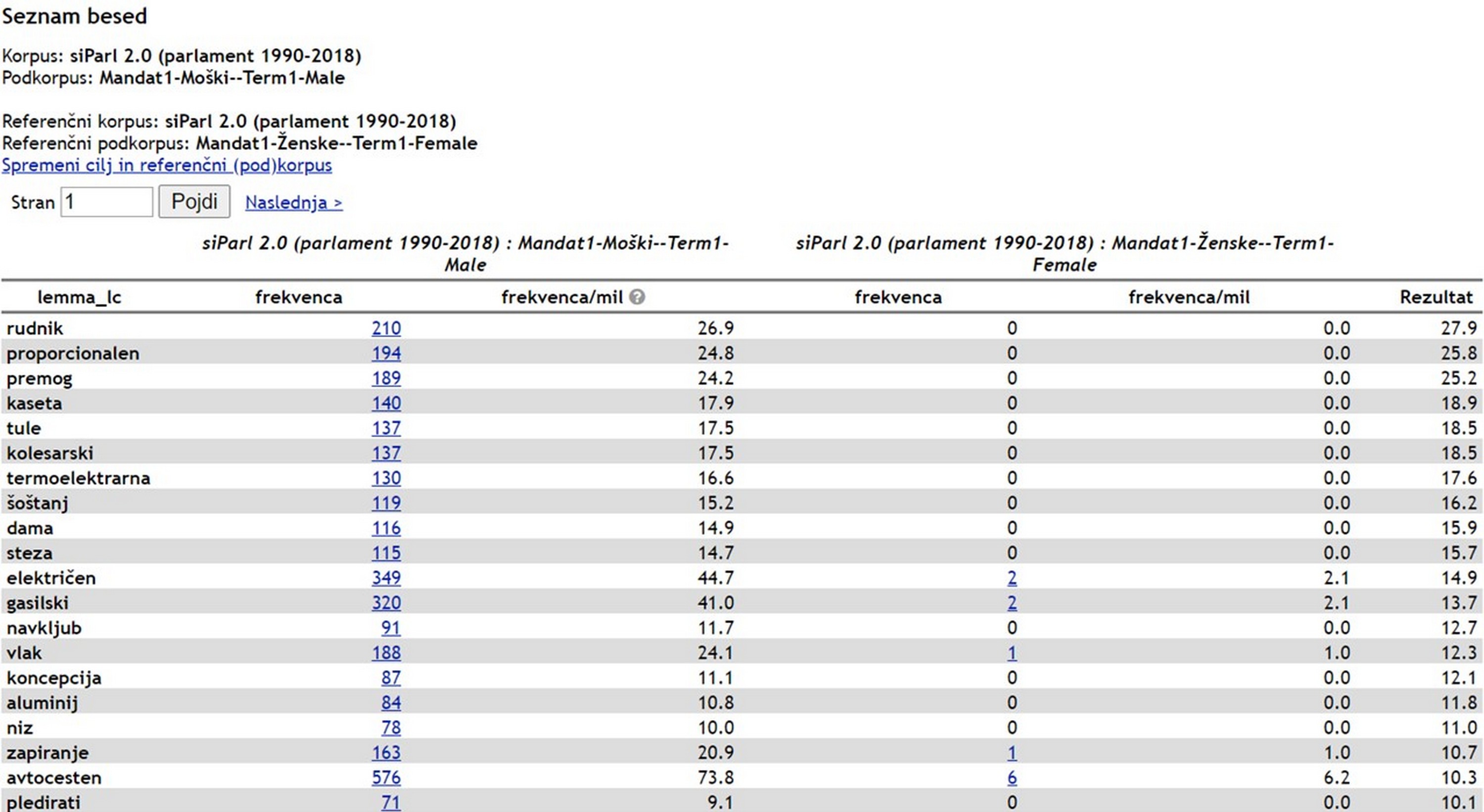
3Slika 4 prikazuje primer dveh frekvenčnih seznamov.
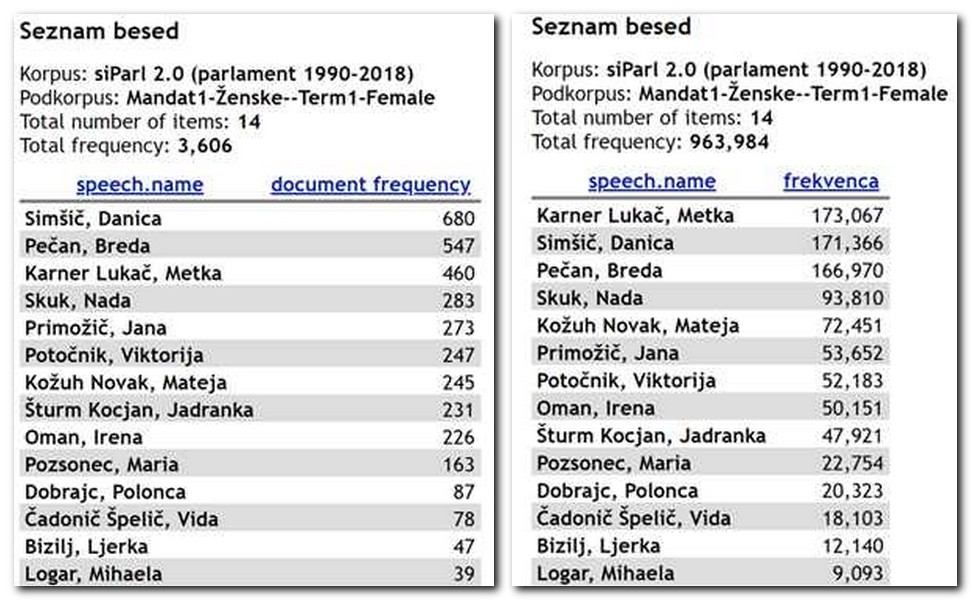
4Kot prikazuje Slika 4, je bilo v prvem mandatu prisotnih 14 poslank, ki so skupno izrekle več kot 3.500 govorov, kar je le malo manj kot milijon pojavnic. Povprečno je to skoraj 260 govorov oziroma 69.000 pojavnic na poslanko. Vendar pa je porazdelitev med poslankami zelo neenakomerna, pri čemer sega od skoraj 700 govorov oziroma več kot 170.000 pojavnic do manj kot 40 govorov oziroma 9.000 pojavnic.
5Po številu govorov je na prvem mestu Danica Simšič, članica Demokratske stranke Slovenije, manjše opozicijske stranke iz prvega mandata. Ta poslanka je prispevala 680 govorov ali skoraj 19 % vseh govorov v celotnem podkorpusu, kar je skoraj 3-kratno povprečje pri ženskah. Podatek o deležu govorov smo pridobili tako, da smo število njenih govorov delili s številom vseh govorov poslank (gl. Slika 4, levo: Total frequency in Simšič, Danica), podatek o razmerju glede na povprečje pa smo pridobili tako, da smo število poslankinih govorov delili s povprečjem števila vseh govorov, ki ga dobimo tako, da skupno število govorov poslank delimo s številom vseh poslank (gl. Slika 4, levo: Total frequency in Total number of items).
6Po številu pojavnic je poslanka z največjim prispevkom v tem podkorpusu Metka Karner Lukač, članica Slovenske ljudske stranke, najstarejše stranke v Sloveniji. Njeni govori vsebujejo 173.067 pojavnic ali 18 % celotnega podkorpusa, kar je skoraj 3-kratnik povprečja. Poslanka z najnižjim številom govorov in pojavnic je Mihaela Logar, prav tako članica Slovenske ljudske stranke, ki je v svojem 4-letnem mandatu spregovorila le 39-krat, v njenih govorih pa je nekaj več kot 9.000 pojavnic, kar je skoraj 20-krat manj od prvouvrščene govorke. Poleg tega je še zanimivo, da približno polovica vseh prispevkov pripada le trem poslankam, in sicer že omenjenima poslankama ter Bredi Pečan, članici Socialnih demokratov, katere govori so bili v povprečju tudi najdaljši. Ta podatek razberemo iz podatkov o povprečni dolžini govorov za posamezno poslanko, pri čemer povprečno dolžino govora izračunamo tako, da število vseh pojavnic za posamezno poslanko (gl. Slika 4, desno) delimo s številom vseh govorov te iste poslanke (gl. Slika 4, levo).
6.2.3. Primerjalna analiza
1Za potrebe primerjalne analize zastopanosti moških in žensk v slovenskem parlamentu skozi čas zabeležimo število poslancev in poslank ter število pojavnic v vsakem od 14 podkorpusov (gl. razdelek 6.2.1 Izdelava podkorpusov). Ker zbirnih tabel s podatki ne dobimo neposredno v konkordančniku, si pomagamo tako, da podatke ročno vnesemo v preglednico, kot prikazuje Tabela 1. Grafični prikaz rezultatov si lahko ogledate na Sliki 5 in Sliki 6.
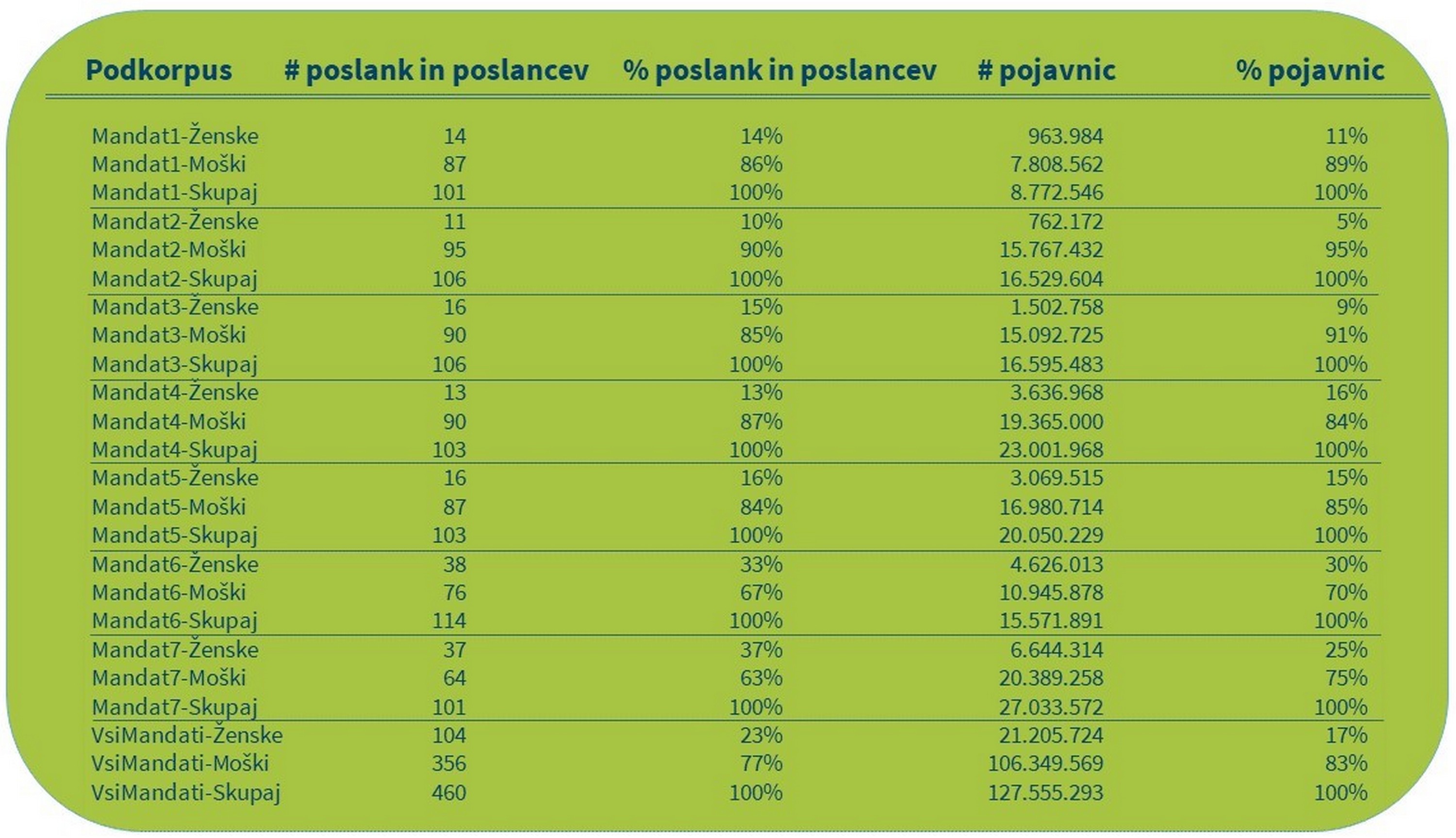
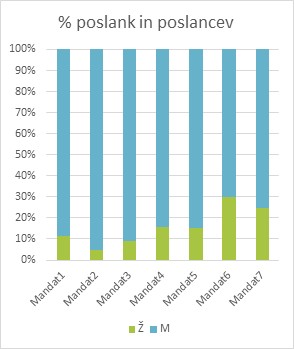
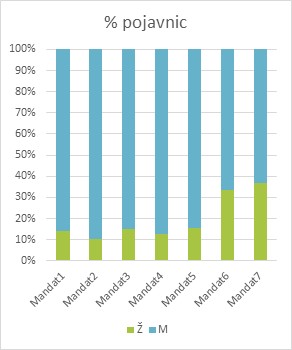
2Rezultati kažejo, da delež pojavnic, ki sestavljajo govore poslank, postopoma narašča skupaj z zastopanostjo žensk v parlamentu. Precejšen skok v zastopanosti žensk je mogoče opaziti predvsem v zadnjih dveh mandatih, vključenih v korpus siParl 2.0, kar je najverjetneje posledica sprejema spolnih kvot, v skladu s katerimi mora biti od leta 2011 na volilnih seznamih 35 % žensk.86 Pomembna pa je ugotovitev, da kljub temu, da so kvote eden najuspešnejših ukrepov za povečanje števila poslank,87 naša korpusna analiza prikazuje velika odstopanja med številom govork in številom pojavnic v njihovih govorih. Rezultati volitev so enostavno dostopni in raziskovalci in analitiki jih pogosto uporabljajo, število in vsebina govorov pa sta veliko težje dostopna, zato ju raziskovalci izven korpusnega jezikoslovja precej manj izčrpno preučujejo, kar predstavlja vrzel, ki jo želimo s to analizo premostiti. Podatki kažejo jasen trend, da poslanke prispevajo manjši delež vsebine, kot bi pričakovali glede na njihov delež v izbranem mandatu. To velja zlasti za drugi mandat, kjer govori poslank vsebujejo dvakrat manj pojavnic glede na njihovo število. Pravzaprav je le v četrtem mandatu prispevek žensk nekoliko večji od njihovega deleža v parlamentu. Zato lahko sklepamo, da več izvoljenih poslank ne pomeni nujno, da bo njihov glas tudi bolj prisoten v Državnem zboru. Vseeno pa se je v preteklih letih z večanjem števila poslank v parlamentu začelo povečevati tudi število njihovih govorov. Prispevek poslank se je s pičle desetine vseh govorov v parlamentu v prvih petih mandatih povečal na skoraj tretjino v zadnjih dveh mandatih, ki jih pokriva naš korpus.
6.3. NALOGA 2: Ključne teme poslank in poslancev
1Raziskave političnega diskurza žensk so pokazale, da ženske običajno razpravljajo o drugačnih temah kot moški. Več o vplivu spola na jezik si lahko preberete v razdelku 5 Jezik in spol.
2V Nalogi 2 želimo na podlagi govorov iz korpusa siParl 2.0 primerjati teme, o katerih razpravljajo poslanke in poslanci. Za nekatere parlamentarne korpuse je klasifikacija tem že na voljo,88 za korpus siParl 2.0 pa to ne velja. Klasifikacijo tem je mogoče izvesti samodejno, kot v članku Analysis of policy agendas,89 vendar pa je cilj tega gradiva pokazati učinkovitost raziskav parlamentarnih korpusov zgolj prek uporabe konkordančnikov, torej brez kakršnegakoli znanja programiranja, zaradi česar smo izbrali ročni pristop v dveh korakih. Ročni pristopi so še posebej primerni za zelo specifično razvrščanje tem, kot to velja za našo analizo, za katero še ne obstajajo računalniški modeli ali učne množice za razvoj takih modelov. Pri tem je treba opozoriti, da lahko tako pri samodejnem kot pri ročnem razvrščanju pride do napak, vendar lahko pri ročnem označevanju število napak, ki so posledica nenatančnosti ali pa tudi pristranskosti označevalca oziroma označevalke, zmanjšamo z večjim številom označevalk oz. označevalcev, s čimer pridobimo vpogled v stopnjo ujemanja med njimi, za nadaljnje delo pa lahko upoštevamo temo, ki jo je izbrala večina, oz. vse pripisane teme.
6.3.1. Luščenje ključnih besed
1V tej nalogi bomo uporabili uveljavljeno tehniko korpusne analize, ki ji rečemo luščenje ključnih besed.90 S to tehniko izbrani korpus primerjamo z referenčnim korpusom in tako pridobimo najbolj značilno besedišče izbranega korpusa, torej (pod)korpusa, ki ga analiziramo. Referenčni korpus pa je običajno velik reprezentativni korpus ustreznega jezika, lahko pa je tudi katerikoli drug (pod)korpus, ki ga želimo uporabiti kot referenčno točko za primerjavo. V tej nalogi bomo primerjali podkorpusa govorov poslank in poslancev za posamezni mandat. Tako bomo pridobili podatke, na podlagi katerih bomo lahko opredelili najbolj izstopajoče teme v slovenskem parlamentu.
2Videoposnetek, ki prikazuje izdelavo seznama ključnih besed v konkordančniku NoSketchEngine, je na voljo na https://youtu.be/DMiZP6f4qI8.
3Ustvarjeni seznami ključnih besed, prikazanih kot leme s poenoteno malo začetnico, so na voljo tukaj:
4Sezname ključnih besed za vse štiri podkorpuse izvozimo v preglednico in jih ročno označimo (gl. razdelek 6.3.3 Primerjalna analiza).
5Sliki 7 in 8 prikazujeta prvih 20 ključnih besed poslank in poslancev v sedmem mandatu.95 Opazimo lahko velike razlike. Večina vseh prikazanih ključnih besed poslank je povezana s področjem zdravstvenega varstva, medtem ko ključne besede govorov poslancev pripadajo področjem zunanjih zadev, infrastrukture in pravosodja.
6.3.2. Analiza konkordanc
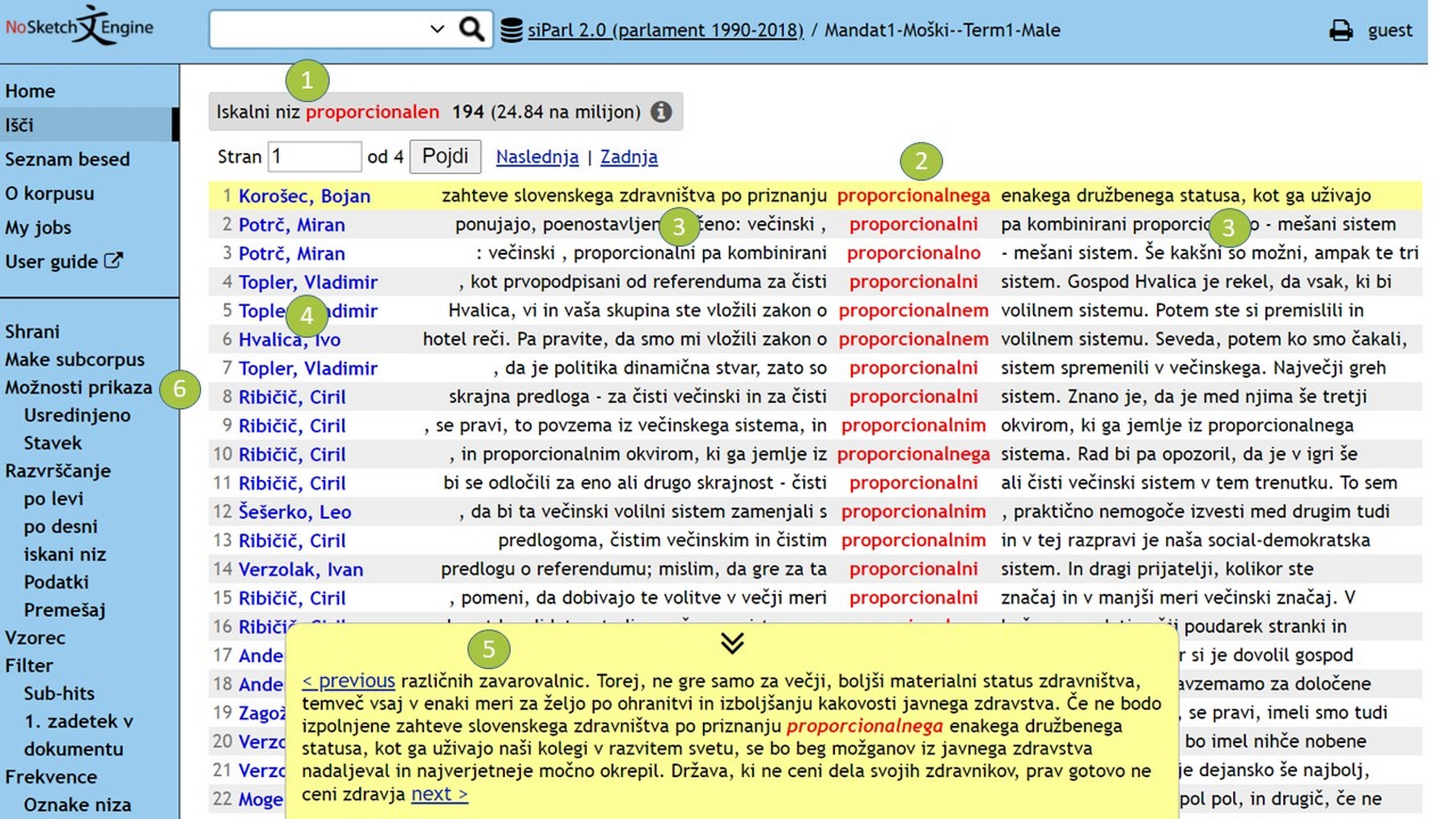
1Za nadaljnjo analizo izberemo prvih 100 ključnih lem z vsakega od štirih seznamov ključnih besed, pri čemer ne upoštevamo osebnih lastnih imen. Naš cilj je ročno kategorizirati leme, in sicer glede na prevladujočo temo, ki jo prepoznamo pri pregledu konkordanc 96 za izbrano lemo. Konkordančni niz vsebuje seznam vseh pojavitev iskane pojavnice v kontekstu, kot prikazuje Slika 9:
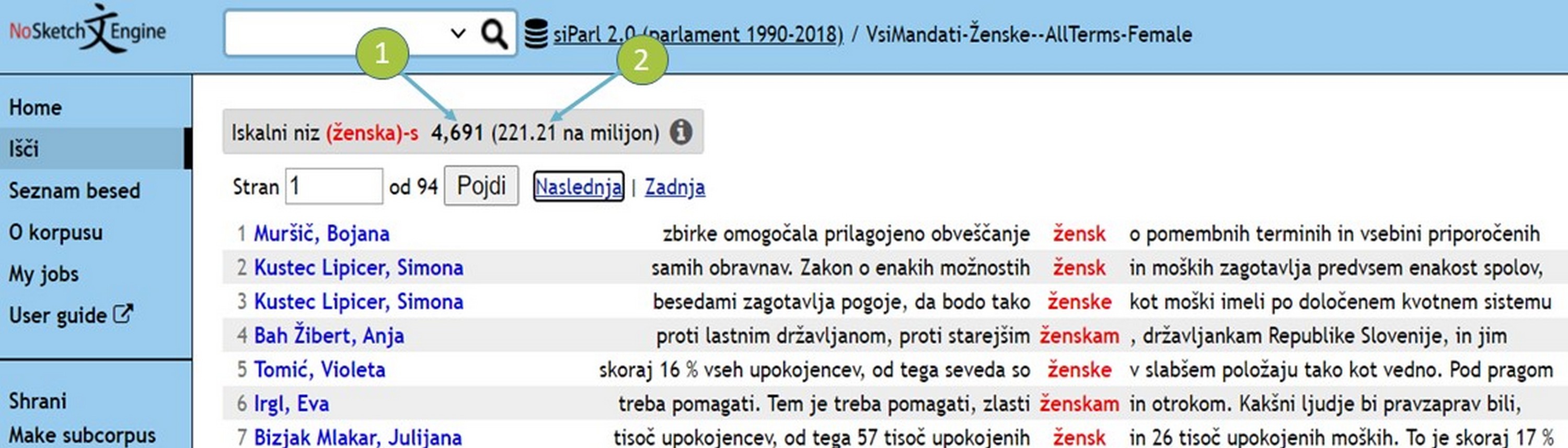
- Konkordance je mogoče neposredno prikazati s klikom leme na seznamu ključnih besed. Prikaže se stran, kjer je na vrhu zaslona prikazana izbrana lema z vsemi zadetki (gl. številko 1).
- Besede v rdeči barvi na sredini zaslona (gl. številko 2) so zadetki iskane besede v našem podkorpusu, besedilo v črni barvi (gl. številko 3) pa je kontekst.
- Besedilo v modri barvi na levi (gl. številko 4) so metapodatki. V našem primeru je prikazan podatek o govorcu.
- S klikom želene konkordance lahko še dodatno razširimo kontekst (gl. številko 5). Na podoben način lahko s klikom govorca pridobimo več metapodatkov.
- Prikaz lahko tudi prilagodimo, in sicer prek Možnosti prikaza (gl. številko 6), ter prikažemo več metapodatkov ali širši kontekst.
6.3.3. Primerjalna analiza
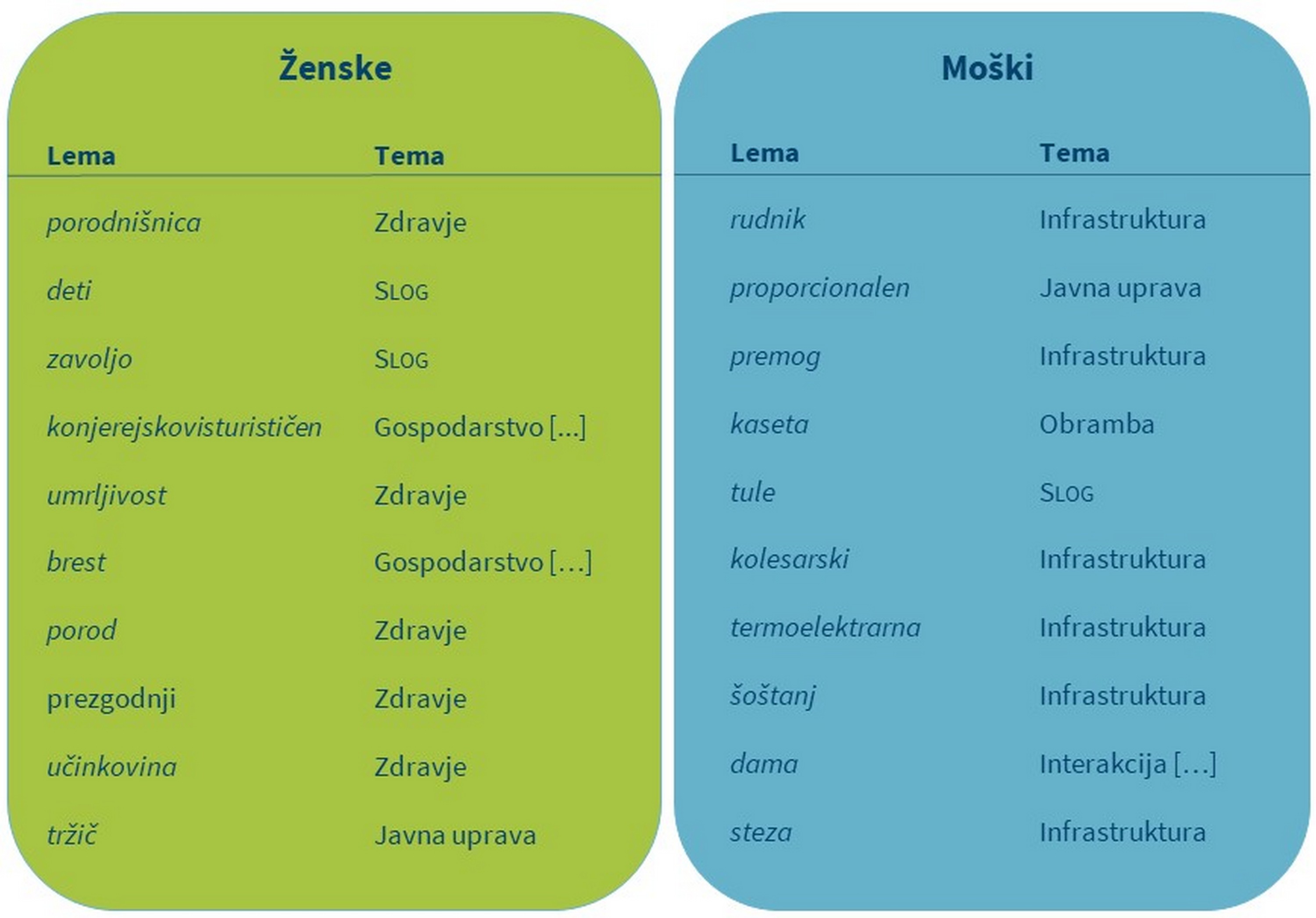
1Parlament je v prvi vrsti zakonodajno telo, v katerem potekajo zakonodajne in proračunske razprave, ki so strukturirane po ministrstvih. Zato nam seznam 14 ministrstev trenutne slovenske vlade 98 služi kot seznam kategorij za ročno označevanje tem. Kategorije so navedene v Tabeli 2. Lahko bi uporabili tudi številne druge sezname tem, vendar je takšen nabor tem po našem mnenju najbolj naravna izbira v specifičnem okolju parlamentarnega diskurza. Tem 14 vsebinskim kategorijam dodamo še 4 tehnične kategorije za ključne besede, ki jih ni mogoče uvrstiti drugam: razno – za ključne besede, uporabljene v razpravah o več različnih temah, slog – za očitne pogovorne ali žargonske ključne besede, ki so izrazito značilne za posamezne govorce, ideologija – za ključne besede, uporabljene za ideološko označevanje (npr. partijski, socialist), in interakcija/postopkovnik – za ključne besede, ki naslavljajo druge poslance ali pa so del postopkovnika. V Tabeli 3 so navedeni ponazoritveni primeri ročno pripisanih tem za prvih 10 ključnih besed poslank in poslancev.

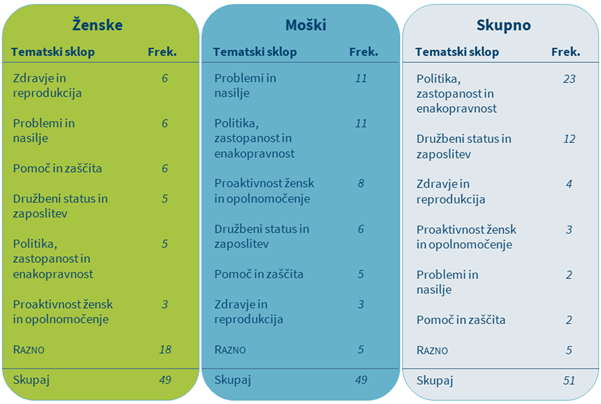
2Tabeli 4 in 5 vsebujeta povzetek rezultatov ročnega označevanja prvih 100 ključnih lem poslank in poslancev v prvem in sedmem mandatu. Rezultati kažejo, da je nabor tem skozi čas in med spoloma primerljiv. Kljub podobnemu številu opredeljenih vsebinskih tem se poslanci in poslanke pri najbolj izpostavljenih tematikah zelo razlikujejo.
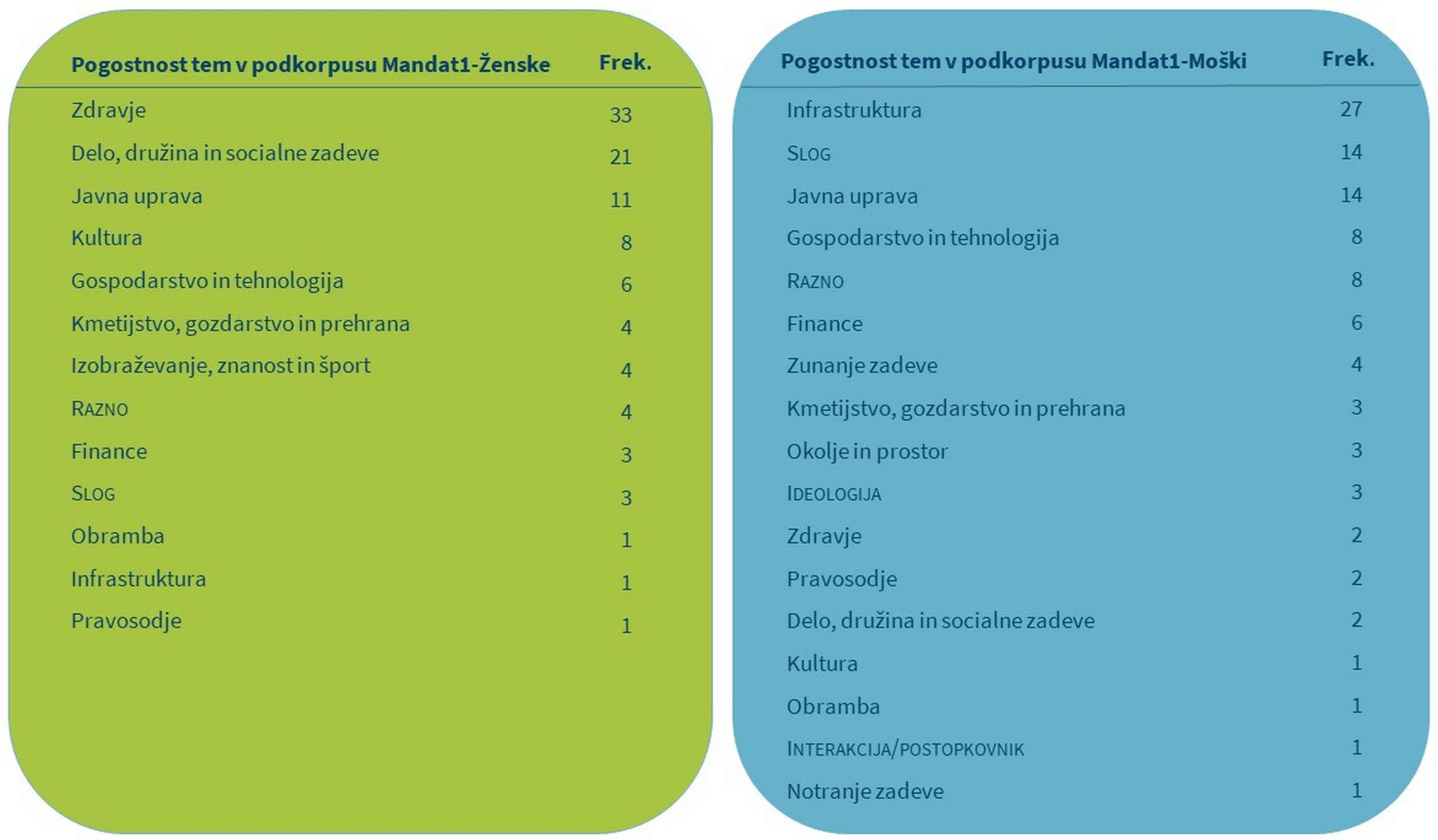
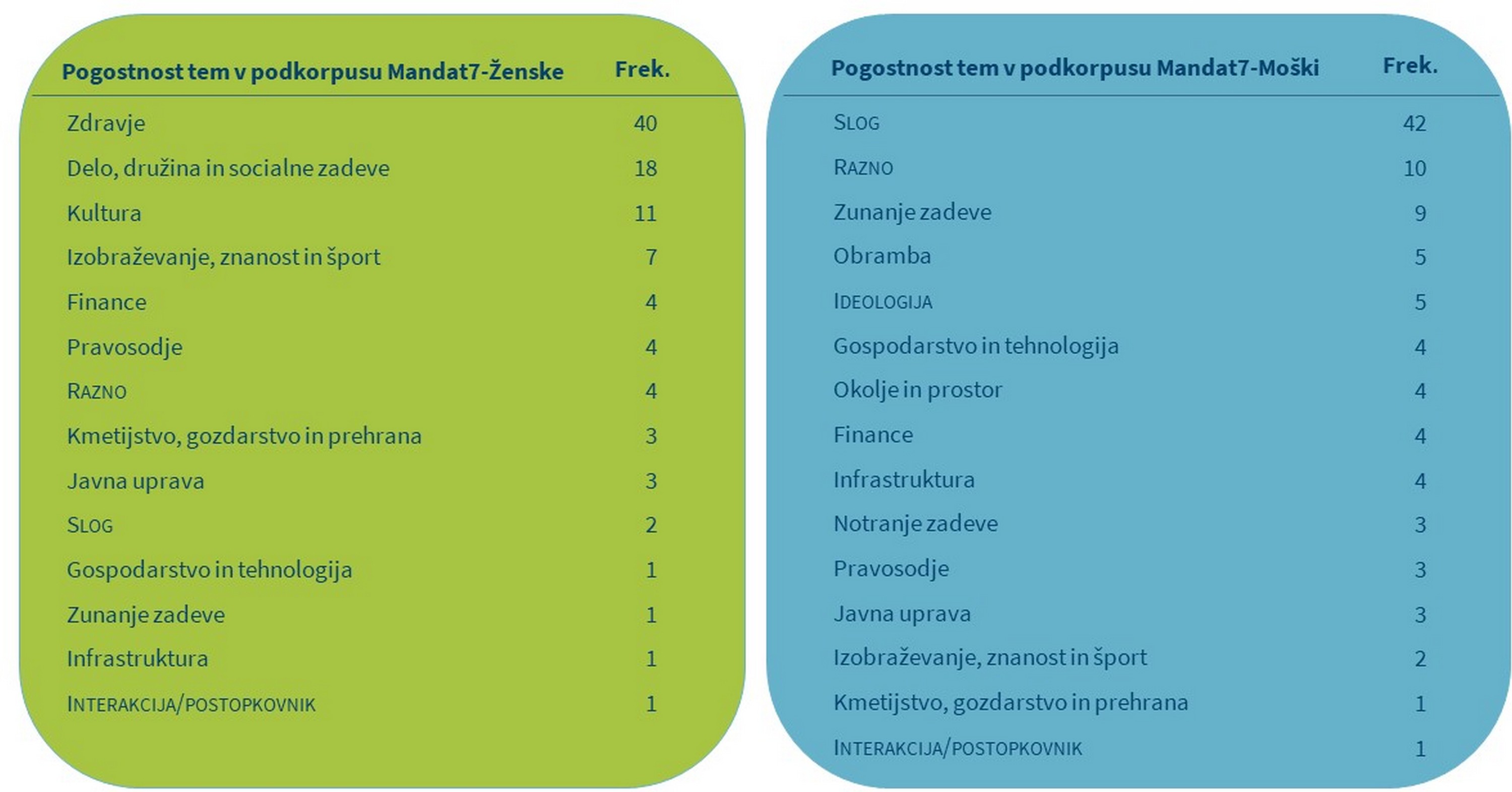
3V prvem mandatu večina (54 %) vseh analiziranih ključnih besed poslank spada v dve tematski kategoriji: Zdravje in Delo, družina in socialne zadeve, pri poslancih pa sta najpogostejši temi s podobnim deležem (55 %) Infrastruktura in Javna uprava. V sedmem mandatu sta najpogostejši temi poslank enaki kot v prvem mandatu, vendar predstavljata večji delež ključnih besed (58 %), pri poslancih pa je najpogostejša tema postala Zunanje zadeve. Razdelitve tem med spoloma ni mogoče v celoti razložiti s korpusno analizo, vendar pa dobljeni rezultati, ki pri poslankah kažejo izrazito zanimanje za zdravstvene in socialnovarstvene teme, pri poslancih pa premik z infrastrukturnih tematik na zunanjepolitične, zelo nazorno odražajo stanje v družbi. V času neodvisnosti je morala novonastala država oblikovati javno upravo in izgraditi infrastrukturo, za kar so bile v prvem mandatu potrebne intenzivne razprave. Zadnji mandat pa zaznamujejo živahna mednarodna trgovina in večje mednarodne varnostne grožnje, kar vpliva na zakonodajne in proračunske odločitve. V sedmem mandatu lahko še vedno zasledimo poudarjeno zanimanje za socialnovarstvene tematike, poleg tega pa tudi intenzivnejše razprave s področja zdravstva, kar je v veliki meri posledica močnega pritiska na proračun zaradi hude gospodarske krize v tistem obdobju, ki je negativno vplivala tudi na že propadajoči sistem javnega zdravstva.
4Opazimo lahko tudi, da v prvem mandatu poslanci in poslanke namenjajo skoraj enako pozornost (glede na delež analiziranih ključnih besed) večjemu številu tem kot v sedmem mandatu (pet skupnih tem z enako pomembnostjo v prvem mandatu oz. tri skupne teme v sedmem mandatu). V prvem mandatu tako poslanci le rahlo pogosteje kot poslanke razpravljajo o Javni upravi (M: 14 %, Ž: 11 %), Gospodarstvu in tehnologiji (M: 8 %, Ž: 6 %) ter Pravosodju (M: 2 %, Ž: 1%), poslanke pa nekaj pogosteje o Kmetijstvu, gozdarstvu in prehrani (M: 3 %, Ž: 4 %), medtem ko vsi razpravljajo enako pogosto o Obrambi (1 %). V sedmem mandatu so glede na delež analiziranih ključnih besed poslankam in poslancem enako pomembne zgolj tri teme, in sicer Finance (4 %), Pravosodje (3 %) in Javna uprava (3 %). Za poglobitev rezultatov bi bilo zanimivo raziskati, na kakšne načine poslanke in poslanci pristopajo k tem skupnim temam in o njih razpravljajo.
5Med temami, ki se pojavijo zgolj v podkorpusu govorov poslank, najdemo Izobraževanje, znanost in šport v prvem mandatu ter Zdravje, Delo, družino in socialne zadeve ter Kulturo v sedmem mandatu. Teme, ki se pojavijo zgolj pri poslancih, pa so Okolje in prostor ter Notranje zadeve v obeh parlamentarnih mandatih, Zunanje zadeve (v prvem mandatu) in Obramba (v sedmem mandatu). Presenetljivo je, da se najpogostejše tri teme poslank sploh ne pojavijo na seznamu tem poslancev, medtem ko se najpogostejše teme poslancev (Infrastruktura, Javna uprava, Zunanje zadeve) pojavijo na seznamu tem poslank, čeprav je njihov delež majhen. Poleg tega je zanimivo, da tema Gospodarstvo in tehnologija pri poslankah izgubi na pomembnosti med prvim in sedmim mandatom, medtem ko to ne velja za poslance.
6Rezultati poleg različnih področij zanimanja kažejo tudi na slogovne razlike v razpravah poslank in poslancev. V obeh mandatih so poslanci uporabili precej več slogovno zaznamovanih besed (tj. očitnih pogovornih ali žargonskih besed, ki so izrazito značilne za posamezne govorce) kot poslanke. Uporaba takšnih besed pri poslancih se je v sedmem mandatu v primerjavi s prvim mandatom potrojila, kar po eni strani kaže na večjo sproščenost poslancev na splošno, po drugi pa označuje spremembo v kulturi razpravljanja, ki je v zadnjih dveh desetletjih postala živahnejša in bolj neformalna. Opazimo lahko tudi, da so ideološke besede, ki običajno delujejo razdvajajoče, značilne le za poslance. To je v skladu z literaturo, kjer avtorji ugotavljajo, da so moške sporazumevalne strategije bolj agresivne in tekmovalne, medtem ko je ženski slog sporazumevanja bolj sodelovalen.99 Vendar naj opozorimo, da bi bilo treba te zaključke preveriti s podrobnejšo analizo, saj nekatere sodobne raziskave kažejo, da na sporazumevanje vplivajo številni dejavniki in je zato razlikovanje med moškim in ženskim načinom sporazumevanja pogosto preveč simplistično.100
7Naša analiza kaže tudi na opazne razlike v vlogah in zanimanjih poslank in poslancev, kar je v skladu s prejšnjimi raziskavami, iz katerih je razvidno, da se ženske v primerjavi z moškimi bolj osredotočajo na t. i. mehka zakonodajna področja. Diahrone primerjave razkrivajo, da temi Zdravje in Socialne zadeve ostajata med prednostnimi zanimanji poslank, osredotočenost poslancev pa se je premaknila s tem Infrastruktura in Javna uprava na Zunanje zadeve. V prvem mandatu je bila najpogostejša skupna tema Javna uprava, v zadnjem mandatu pa so poslanke in poslanci najpogosteje razpravljali o temi Finance. To pa ne pomeni, da poslanke zdaj več razpravljajo o t. i. trdih zakonodajnih področjih. Pravzaprav je ravno nasprotno, saj analiza kaže, da so se poslanke v sedmem mandatu celo bolj osredotočale na t. i. mehka zakonodajna področja kot v prvem mandatu.
6.4. NALOGA 3: Obravnava tematik, povezanih z ženskami
1Ta naloga se naslanja na sorodne raziskave,101 v katerih so raziskovalci ugotavljali, kako pogosto so bile v parlamentarni zgodovini naslovljena vprašanja enakosti spolov (npr. pravice žensk, diskriminacija itd.) ter kdo in na kakšen način je takšna vprašanja odpiral. Zanimivo je, da je vpliv spola očitno opazen tudi v državah z visokim deležem žensk v parlamentu. Ena takšnih je Švedska, za katero so Bäck idr.102 ugotovili, da poslanke redkeje razpravljajo o vprašanjih s t. i. trdih zakonodajnih področij. Antić Gaber in Ilonszki103 pravita, da družba običajno pričakuje, da bodo poslanke dejavne na drugih področjih politike kot moški. Pri tem gre, kot to ugotavljajo politologi,104 za področja politike, ki so še posebej povezana z ženskami zaradi njihove zgodovinske vloge v družbi ali neposrednega vpliva na življenje žensk.
2Ker se pri vprašanjih enakosti spolov še vedno največkrat govori o neenaki vlogi žensk v družbi in njihovem posebnem položaju, iz katerega izhajajo tako določene pravice in teme, ki se tičejo njihovega življenja, kot tudi diskriminatorne prakse, bomo v Nalogi 3 raziskali, katere tematike, povezane z ženskami, prevladujejo v parlamentarnih razpravah in kako pogosto se o njih razpravlja, pri čemer se bomo osredotočili na uporabo samostalnika »ženska« kot eksplicitnega pokazatelja razprav o teh tematikah.
6.4.1. Delo s frekvencami
1V tem delu nas najprej zanima, kako pogosto poslanci in poslanke uporabljajo lemo samostalnika »ženska« v različnih časovnih obdobjih (1992–2018). Izvedemo poizvedbe v vseh podkorpusih in v preglednico zabeležimo podatke o frekvenci, kot prikazuje Tabela 6. Ker želimo primerjati podkorpusa različnih velikosti, moramo namesto absolutne frekvence uporabiti normalizirano frekvenco,105 pri kateri je uporabljeno enako skupno število vseh besed v (pod)korpusu. Absolutna frekvenca je v primeru primerjave korpusov različnih velikosti namreč lahko zavajajoča. Če na primer pogledamo podatka o absolutni frekvenci izbrane besede za drugi mandat (Ž: 190; M: 794), bi lahko sklepali, da poslanci uporabijo samostalnik »ženska« štirikrat pogosteje kot poslanke. Ker pa je podkorpus govorov poslank v tem parlamentarnem mandatu veliko manjši od podkorpusa govorov poslancev, nam šele normalizirana frekvenca (v našem primeru na milijon besed), pove, da so ta samostalnik poslanke izrekle pravzaprav petkrat pogosteje (249,29) kot poslanci (50,36).
2Prikaz poizvedbe v konkordančniku NoSketchEngine za lemo samostalnika »ženska« si lahko ogledate v videoposnetku o luščenju kolokacij (min. 00:10–1:13) na povezavi https://youtu.be/ENXP8TrH42U.
3Konkordančni niz za lemo samostalnika »ženska« je na voljo tukaj:
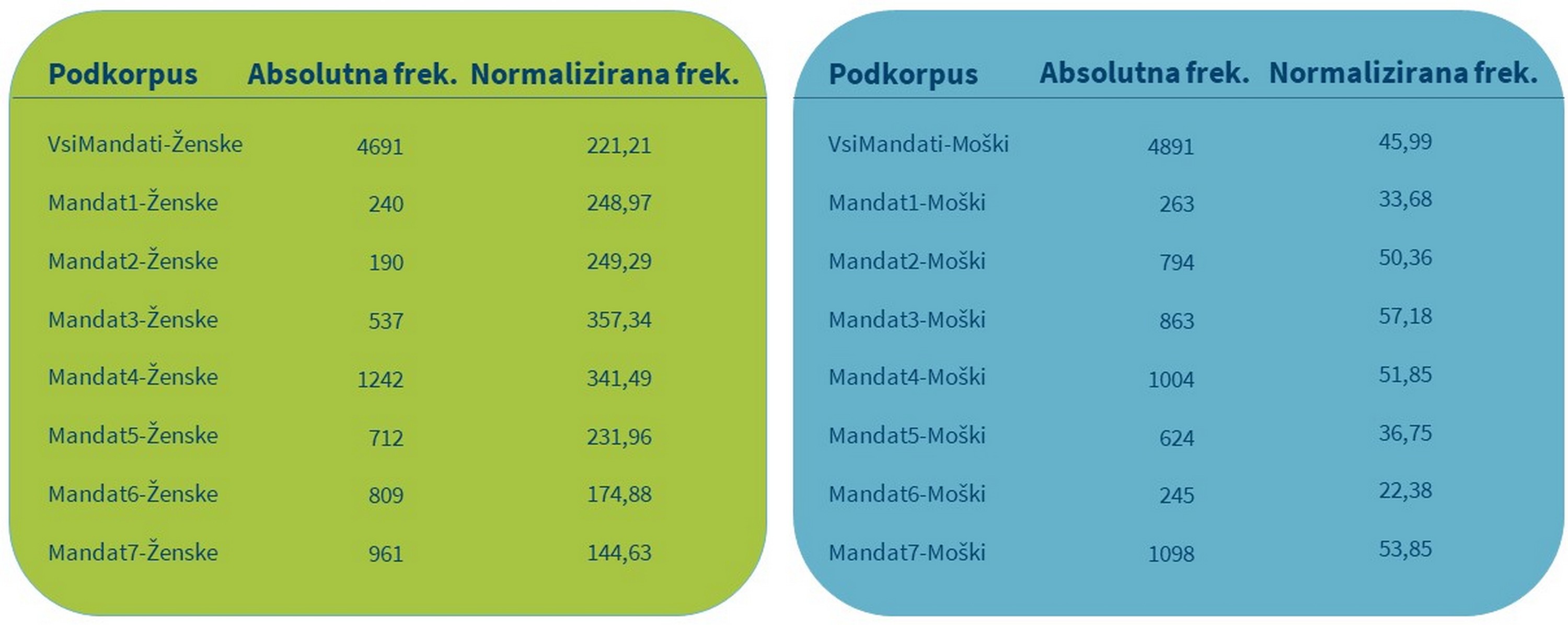
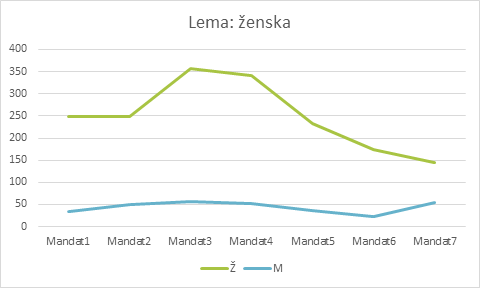
4Na splošno je normalizirana frekvenca iskane besede za celotno časovno obdobje, ki ga zajema korpus siParl 2.0, skoraj petkrat višja v podkorpusu govorov poslank kot v podkorpusu govorov poslancev (221,21 proti 45,99). Kot je razvidno iz Slike 10, poslanke v svojih govorih pogosteje omenjajo ženske kot poslanci. Čeprav je v obdobju med drugim in četrtim mandatom (1996–2008) mogoče opaziti intenzivnejšo obravnavo teh področij pri poslankah, je v zadnjih mandatih njihovo zanimanje za ta področja izrazito usahnilo.
5Najbolj presenetljive rezultate pri poslankah smo odkrili v tretjem in petem mandatu. V tretjem mandatu je normalizirana frekvenca iskane besede dosegla rekordno visoko stopnjo, kar je lahko posledica manjšega števila poslank v prejšnjih dveh parlamentarnih mandatih in neenakopravnega položaja žensk v družbi nasploh. Ker pa je enak trend mogoče opaziti tudi v podkorpusu govorov poslancev, se zdi, da so k temu prispevali tudi drugi razlogi. Za boljši vpogled v ta pojav smo izvedli kvalitativno analizo, pri kateri smo pregledali 50 konkordanc petih najdejavnejših poslancev. Iz konkordanc je razvidno, da se je v tistem času veliko razpravljalo o zakonodaji prav v zvezi z vprašanji enakosti spolov (npr. zakonodaja o enakih možnostih in spolnih kvotah). Skoraj desetletje pozneje, v petem mandatu, se je število omemb iskane besede v podkorpusu govorov poslank nenadoma zmanjšalo in padlo celo pod vrednost frekvence pred letom 2000, kljub precej večjemu številu poslank v parlamentu. Peti mandat je potekal v obdobju velike svetovne gospodarske krize, ki je Slovenijo močno prizadela in je bila verjetno osrednji predmet parlamentarnih razprav, vendar bi bilo to treba potrditi z nadaljnjo raziskavo in kontekstualizacijo ob uporabi kvalitativnih metod, kot je analiza konkordanc.
6Zanimivo je tudi, da se v četrtem mandatu kljub drugemu najnižjemu številu poslank samostalnik »ženska« še vedno zelo pogosto pojavlja v primerjavi s šestim in sedmim mandatom, kjer je bilo število poslank precej večje, frekvenca iskane besede pa skoraj dvakrat nižja. Kot smo opazili že pri splošnem doprinosu poslank k razpravam (gl. razdelek 6.2.3 Primerjalna analiza), kjer smo odkrili veliko razhajanje med številom poslank in številom besed, ki so jih izrekle, ti rezultati znova kažejo, da zgolj večje število poslank ne zagotavlja intenzivnejše razprave o tematikah, ki zadevajo ženske.
6.4.2. Luščenje kolokacij
1Predstavili bomo še eno priljubljeno tehniko korpusne analize, in sicer luščenje kolokacij.107 S to tehniko, ki temelji na statističnih testih, pridobimo seznam besed, ki se ob jedrni besedi pojavljajo pogosteje, kot bi se zgolj po naključju. Kolokacije se najpogosteje uporabljajo v leksikografiji in na sorodnih področjih uporabnega jezikoslovja, mi pa jih bomo uporabili kot sredstvo za raziskovanje konceptov ali tem, o katerih se razpravlja v parlamentu.
2Da bi lahko ugotovili, o katerih tematikah, ki zadevajo ženske, se v parlamentu največ razpravlja, bomo analizirali kolokacije samostalnika »ženska« v dveh podkorpusih, ki vsebujeta govore poslank oziroma poslancev iz vseh sedmih mandatov, torej podkorpusa VsiMandati-Ženske in VsiMandati-Moški.
3Videoposnetek, ki prikazuje postopek luščenja kolokacij v konkordančniku NoSketchEngine, je na voljo na https://youtu.be/ENXP8TrH42U.
4Izluščimo kolokacije v razponu ene besede levo in ene besede desno od jedrne besede (tj. leme samostalnika »ženska«), pri čemer se mora kolokacijski kandidat (tj. beseda, ki se tipično pojavlja ob jedrni besedi) v korpusu pojaviti vsaj petkrat, skupaj z jedrno besedo v določenem razponu pa vsaj trikrat. Razpon in najnižjo frekvenco je mogoče nastaviti ročno in sta odvisna od jedrne besede, velikosti korpusa ter cilja naše raziskave. Ker želimo analizo v tem gradivu omejiti na ustaljene besedne zveze, uporabljamo ozek razpon in stroga merila glede frekvence.
5Za določanje trdnosti kolokacij uporabimo statistično mero logDice.108 Čeprav konkordančnik NoSketch Engine ponuja tudi druge mere, po katerih se izračuna trdnost kolokacij, kot sta Mutual Information ali T-score, izberemo mero logDice, ker nanjo ne vpliva velikost korpusa in so zato rezultati uporabni za primerjalno analizo tudi v primeru uporabe podkorpusov različnih velikosti, kot to velja za našo analizo.
6Seznama kolokacij za lemo samostalnika »ženska« sta na voljo tukaj:
7Oba seznama kolokacij uvozimo v preglednico in ju ročno analiziramo (gl. razdelek 6.4.3 Primerjalna analiza).
6.4.3. Primerjalna analiza
1Z vsakega seznama vzamemo prvih 100 kolokacijskih kandidatov (tj. besed, ki se tipično pojavljajo ob jedrni besedi in torej skupaj z njo tvorijo kolokacijo) in jih ročno razdelimo v tri kategorije: ženske, moški in skupno.111 Nato vsako besedo razvrstimo v enega od sedmih tematskih sklopov, ki smo jih oblikovali na podlagi predhodnega pregleda konkordanc, kot prikazuje Tabela 7. Kolokacijskim kandidatom, ki so slovnične besede (na primer predlogi) in niso uporabljeni v konkordancah na eno prevladujočo temo, pripišemo oznako Razno.
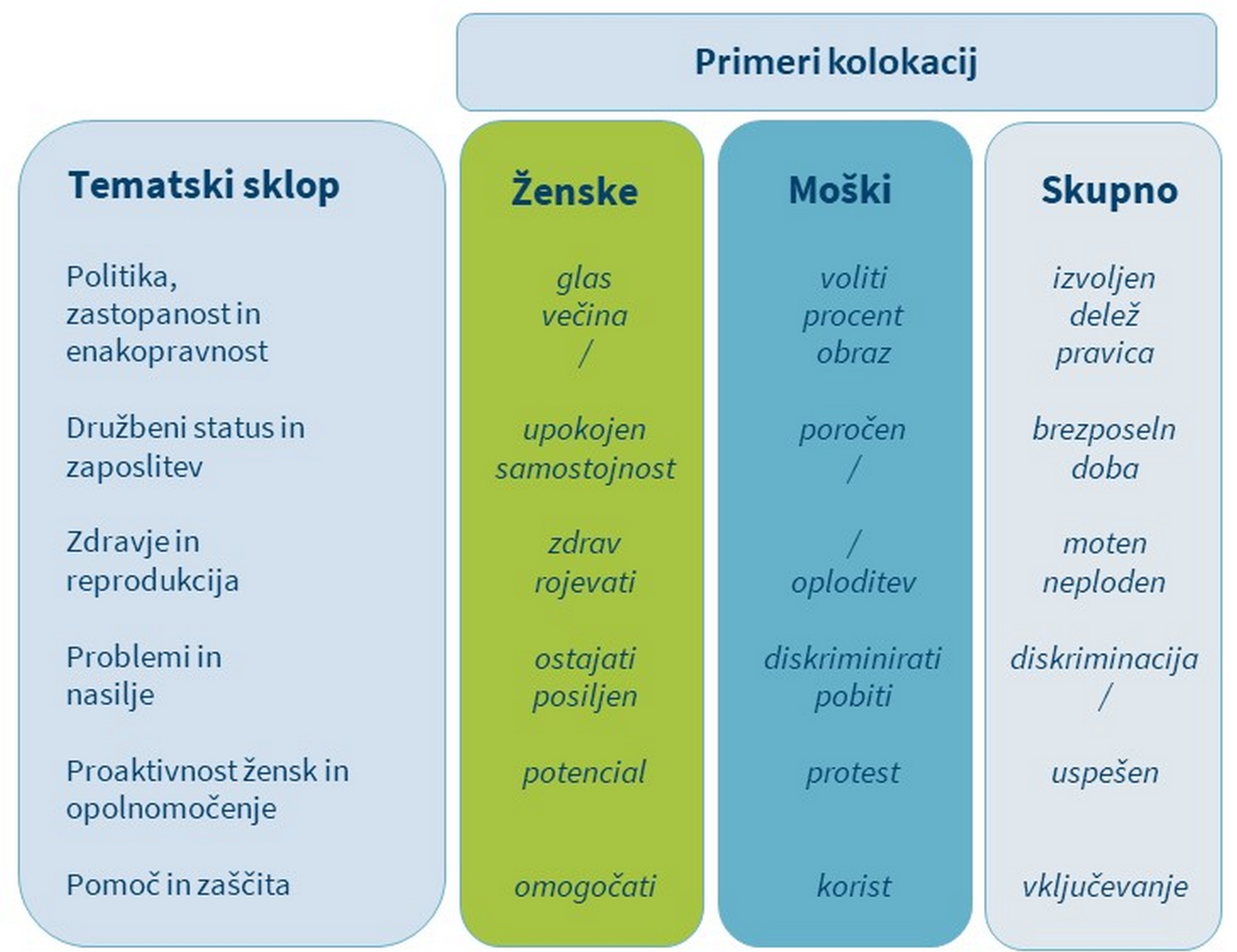
2Rezultati, predstavljeni v Tabeli 8, kažejo, da se nekaj več kot polovica kolokacij
3(51 %) pojavlja tako pri poslankah kot pri poslancih, kar kaže na skupne točke v razumevanju položaja žensk v sodobni družbi. Velika večina skupnih kolokacij (skoraj 70 %) spada v prva dva tematska sklopa: Politika, zastopanost in enakopravnost in Družbeni status in zaposlitev, in se nanaša na koncepte, povezane z zastopanostjo žensk (npr. »participacija«), njihovim družbenim položajem (npr. »samski«) in enakostjo (npr. »emancipacija«).
4Opazimo lahko tudi, da so v podkorpusu govorov poslank primerljivo zastopani vsi tematski sklopi razen enega, skupaj pa pokrivajo skoraj 60 % kolokacij. Edina izjema je torej tematski sklop Proaktivnost žensk in opolnomočenje. Kolokacije, ki spadajo v ta tematski sklop, so približno dvakrat redkejše kot kolokacije iz kateregakoli drugega sklopa. V podkorpusu govorov poslancev večina kolokacij (61 %) spada v tri tematske sklope, in sicer Problemi in nasilje, Politika, zastopanost in enakopravnost in Proaktivnost žensk in opolnomočenje. Poleg tega podroben pregled oznak razkriva, da se poslanci osredotočajo predvsem na družbeni status žensk (npr. »poročen«) in njihove težave (npr. »zatiranje«) ter na njihovo proaktivnost in opolnomočenje (npr. »sposoben«), medtem ko težavam, povezanim z zaposlitvijo in zdravjem žensk, ne posvečajo posebne pozornosti. Kolokacije iz podkorpusa govorov poslank se v prvi vrsti nanašajo na področje zdravstva (npr. »zdrav«) in ukrepe, vezane na pomoč in zaščito (npr. »omogočati«). Tem sledijo kolokacije, ki se nanašajo na družbeni status žensk (npr. »izobrazba«) in nasilje (npr. »posiljen«), kar je spet v nasprotju s podkorpusom govorov poslancev, kjer je večji poudarek na težavah, ki ne vključujejo nasilja (npr. »poniževanje«). Podobno kot v podkorpusu govorov poslancev pa tudi v podkorpusu govorov poslank med prvimi 100 kolokacijskimi kandidati ni besed, povezanih z zaposlitvijo.
5Ti rezultati kažejo, da poslanke poskušajo obravnavati številna vprašanja, s katerimi se ženske srečujejo na različnih področjih življenja, in sicer od zdravstvenih vprašanj do nasilja nad ženskami in težav pri političnem delovanju. Poslanci pa se bolj osredotočajo na neenakopravnost žensk v sodobni družbi in ženske vidijo kot dejavne udeleženke v procesu sprememb. Ti rezultati potrjujejo tudi ugotovitve avtoric Antić Gaber in Ilonszki,112 ki sta opazovali dejavnost žensk v slovenskem parlamentu v krajšem obdobju (1996–2004) in z raznolikimi nekorpusnimi metodami analize pokazali, da med poslankami in poslanci obstaja jasna razlika med zakonodajnimi prioritetami, pri čemer sta opredelili podobne teme kot naša analiza.
6Naša zadnja ugotovitev zadeva veliko število slovničnih besed v podkorpusu govorov poslank, ki so skoraj štirikrat pogostejše kot v podkorpusu govorov poslancev. Slovnične besede kot kolokacijski kandidati v podkorpusu govorov poslank večinoma vključujejo prislove, predloge, veznike, zaimke in števnike, v podkorpusu govorov poslancev pa prevladujejo le števniki. Podobno kot smo ugotovili pri analizi ključnih besed (gl. razdelek 6.3.3 Primerjalna analiza), to znova kaže na drugačen slog razpravljanja pri poslankah. Ta ugotovitev je skladna s sorodnimi raziskavami, v katerih raziskovalci poročajo, da ženske običajno uporabljajo več jezikovnih sredstev, kot so diskurzni omejevalci, vljudnostne oblike in vprašalni pristavki,113 več intenzifikatorjev in (predvsem ocenjevalnih) pridevnikov114 ter več osebnih zaimkov kot moški, ki pri sporazumevanju uporabljajo več števnikov, členov in predlogov.115
7. Zaključki
1Cilj učnega gradiva je bil prikazati uporabnost jezikovnih korpusov za analizo družbenokulturnih pojavov, ki jih lahko raziskujemo na podlagi jezikovne rabe v specializiranem diskurzu. Pokazali smo, kako korpusnoanalitične tehnike omogočajo ugotovitve, ki presegajo intuicijo raziskovalke oz. raziskovalca in tako ponujajo večjo preglednost, objektivnost, zanesljivost in ponovljivost raziskav, kar postajajo vse pomembnejša načela tudi na področju humanistike in družboslovja.
2Glavni doprinos tega učnega gradiva lahko razdelimo na tri dele. Najprej smo pokazali, kako pomembno je razumeti vsebino in strukturo podatkov, ki jih uporabljamo v raziskavi, da lahko čim bolje izkoristimo njihov potencial. Nato smo predstavili, kako lahko nabor standardnih metod korpusne analize uporabimo za veliko več kot le kvantifikacijo in preproste poizvedbe v korpusu. Namesto tega smo rezultate, pridobljene s konkordančnikom, sistematično uporabili kot odskočno desko za podrobno ročno kvalitativno analizo, ki rezultate previdno umešča v ustrezni družbenojezikovni kontekst. Čeprav smo preučevali razprave iz slovenskega parlamenta, so predstavljeni analitični postopki splošni in jih je mogoče uporabiti tudi na (parlamentarnih) korpusih v drugih jezikih.116 Nenazadnje smo analizo umestili tudi v resnično raziskovalno okolje, s čimer smo skušali prikazati uporabnost splošnih metod korpusne analize za obravnavo številnih raziskovalnih vprašanj na področju humanistike in družboslovja.
8. Zahvale
1Izdelavo tega učnega gradiva so podprli CLARIN.SI, slovenski del Evropske infrastrukture za jezikovne vire in tehnologije CLARIN, raziskovalni program ARRS P6-0215 (Slovenski jezik – osnovne, kontrastivne in uporabne študije) in projekt H2020 SSHOC – Social Sciences and Humanities Open Cloud (GA 823782). Posebna zahvala gre tudi red. prof. dr. Milici Antić Gaber, doc. dr. Ireni Selišnik, prof. dr. Cornelii Ilie, Tjaši Cankar, Mladenu Zobcu in Rubenu Rosu za strokovno recenzijo in testiranje učnega gradiva ter vse njihove dragocene komentarje.
Viri in literatura
- Alasuutari, Pertti, Marjaana Rautalin in Jukka Tyrkkö. »The Rise of the Idea of Model in Policymaking: The Case of the British Parliament, 1803–2005.« European Journal of Sociology/Archives Européennes de Sociologie 59, št. 3 (2018): 341–63. https://doi.org/10.1017/S0003975618000164.
- Antić Gaber, Milica in Gabriella Ilonszki. Women in Parliamentary Politics: Hungarian and Slovene Cases Comparur. Ljubljana: Peace Institute, Institute for Contemporary Social and Political Studies, 2003.
- Antić Gaber, Milica in Irena Selišnik. »The Slovene Version of a 'Fast Track' to Political Equality.« Teorija in Praksa 54, št. 2 (2017): 337.
- Bäck, Hanna, Marc Debus in Jochen Müller. »Who Takes the Parliamentary Floor? The Role of Gender in Speech-making in the Swedish Riksdag.« Political Research Quarterly 67, št. 3, (2014): 504–18. https://doi.org/10.1177/1065912914525861 .
- Baker, Paul. Using Corpora to Analyze Gender. London: Bloomsbury, 2014. https://doi.org/10.1177/0075424215578282 .
- Biber, Douglas in Randi Reppen. The Cambridge Handbook of English Corpus Linguistics. Cambridge: Cambridge University Press, 2015. https://doi.org/10.1017/CBO9781139764377 .
- Biel, Łucja, Agnieszka Biernacka in Anna Jopek-Bosiacka. »Collocations of Terms in EU Competition Law: A Corpus Analysis of EU English Collocations.« V: Language and Law, 249–74. Cham: Springer, 2018. https://doi.org/10.1007/978-3-319-90905-9_14.
- Bing, Janet M. in Victoria L. Bergvall. »The Question of Questions: Beyond Binary Thinking.« V: Jennifer Coates (ur.), Language and Gender: A Reader, Vol. 1, 496–510. Oxford: Blackwell, 1998.
- Blaxill, Luke in Kaspar Beelen. »A Feminized Language of Democracy? The Representation of Women at Westminster since 1945.« Twentieth Century British History 27, št. 3 (2016): 412–49. https://doi.org/10.1093/tcbh/hww028 .
- Coates, Jennifer. Women, Men and Language: A Sociolinguistic Account of Gender Differences in Language. London: Longman, 1997.
- Demmen, Jane, Lesley Jeffries in Brian Walker. »Charting the Semantics of Labour Relations in House of Commons Debates Spanning Two Hundred Years.« Doing Politics: Discursivity, Performativity and Mediation in Political Discourse, 80 (2018): 81. https://doi.org/10.1075/dapsac.80.04dem .
- Eckert, Penelope in Sally McConnell-Ginet. Language and Gender. Cambridge: Cambridge University Press, 2013. https://doi.org/10.1017/CBO9781139245883.
- Goddard, Angela in Lindsey M. Patterson. Language and Gender. London: Routledge, 2015.
- Hansen, Dorte H., Costanza Navarretta in Lene Offersgaard. »A Pilot Gender Study of the Danish Parliament Corpus.« V: Darja Fišer, Maria Eskevich in Franciska de Jong (ur.), Proceedings of the Eleventh International Conference on Language Resources and Evaluation. Miyazaki: LREC 2018.
- Ilie, Cornelia. »Gendering Confrontational Rhetoric: Discursive Disorder in the British and Swedish Parliaments.« Democratization 20, št. 3 (2013): 501–21. https://doi.org/10.1080/13510347.2013.786547 .
- Ilie, Cornelia. »Parliamentary Debates. V: Ruth Wodak in Bernhard Forchtner (ur.), The Routledge Handbook of Language and Politics, 309–25. London: Routledge, 2017. https://doi.org/10.4324/9781315183718 .
- Jaworska, Sylvia in Kath Ryan. »Gender and the Language of Pain in Chronic and Terminal Illness: A Corpus-based Discourse Analysis of Patients’ Narratives.« Social Science & Medicine 215 (2018): 107–14. https://doi.org/10.1016/j.socscimed.2018.09.002.
- Karan, Mladen, Jan Šnajder, Daniela Širinić in Goran Glavaš. »Analysis of Policy Agendas: Lessons Learned from Automatic Topic Classification of Croatian Political Texts.« Proceedings of the 10th SIGHUM Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (2016): 12–21. https://doi.org/ 10.18653/v1/W16-2102.
- Kustec Lipicer, Simona, ur. Poslanke Državnega zbora: Uradno in osebno od prvega do sedmega mandata (1992-2017). Ljubljana: Državni zbor, 2017.
- Leijenaar, Monique. How to Create a Gender Balance in Political Decision-making: A Guide to Implementing Policies for Increasing the Participation of Women in Political Decision-making. Luxembourg: Office for Official Publications of the European Communities, 1997.
- Litosseliti, Lia. Gender and Language: Theory and Practice. London: Hodder Arnold, 2006. https://doi.org/10.1111/j.1467-9841.2008.00371_10.x .
- Marshall, Catherine. »Policy Discourse Analysis: Negotiating Gender Equity.« Journal of Education Policy 15, št. 2 (2000): 125–56. https://doi.org/10.1080/026809300285863 .
- McEnery, Tony in Andrew Hardie. Corpus linguistics: Method, Theory and Practice. Cambridge: Cambridge University Press, 2011. https://doi.org/10.1017/CBO9780511981395.
- Mensah, Eric O. in Sandra F. Wood. »Articulations of Feminine Voices in Ghana’s Parliament: A Study of the Hansard from 2010-2011.« AFRREV LALIGENS: An International Journal of Language, Literature and Gender Studies 7, št. 2 (2018): 61–77. https://doi.org/ 10.4314/laligens.v7i2.6.
- Mollin, Sandra. »The Hansard Hazard: Gauging the Accuracy of British Parliamentary Transcripts.« Corpora 2, št. 2 (2007): 187–210. https://doi.org/10.3366/cor.2007.2.2.187.
- Nanni, Federico, Mahmoud Osman, Yi-Ru Cheng, Simone Paolo Ponzetto in Laura Dietz. »UKParl: A Semantified and Topically Organized Corpus of Political Speeches.« V: Darja Fišer, Maria Eskevich in Franciska de Jong (ur.), Proceedings of the Eleventh International Conference on Language Resources and Evaluation. Miyazaki: LREC 2018.
- Newman, Matthew L., Clara J. Groom, Lori D. Handelman in James W. Pennebaker. »Gender Differences in Language Use: An Analysis of 14,000 Text Samples.« Discourse Processes 45, št. 3 (2008), 211–36. https://doi.org/10.1080/01638530802073712 .
- Osborn, Tracey L. How Women Represent Women: Political Parties, Gender and Representation in the State Legislatures. Oxford: Oxford University Press, 2012. https://doi.org/10.1093/acprof:oso/9780199845347.001.0001.
- Pančur, Andrej, Tomaž Erjavec, Mihael Ojsteršek, Mojca Šorn in Neja Blaj Hribar. Slovenian Parliamentary Corpus (1990-2018) siParl 2.0. Slovenian language resource repository CLARIN.SI, 2020.
- Poynton, Cate. Language and Gender: Making the difference. Oxford: Oxford University Press, 1989.
- Rix, Kathryn. »‘Whatever Passed in Parliament Ought to be Communicated to the Public’: Reporting the Proceedings of the Reformed Commons, 1833–50.« Parliamentary History 33, št. 3 (2014): 453–74. https://doi.org/10.1111/1750-0206.12106.
- Wängnerud, Lena. »Intressen kontra stereotyper. Varför finns det kvinnliga och manliga politikområden i riksdagen?.« Statsvetenskaplig Tidskrift 99, št. 2 (1996).
- Wodak, Ruth. »Pragmatics and Critical Discourse Analysis: A Cross-disciplinary Inquiry.« Pragmatics & Cognition 15 (2007): 203–25. https://doi.org/10.1075/pc.15.1.13wod.
- Wolbrecht, Christina. »Female Legislators and the Women’s Rights Agenda: From Feminine Mystique to Feminist Era.« V: Cindy S. Rosenthal (ur.), Women transforming congress, 170–97. Norman: University of Oklahoma Press, 2002.
Darja Fišer, Kristina Pahor de Maiti
"FIRST, I’M A FEMALE POLITICIAN, NOT A MALE ONE, AND SECOND …”
A CORPUS APPROACH TO PARLIAMENTARY DISCOURSE RESEARCH
SUMMARY
1Parliaments represent the main fora for political debate that shapes legislation which directly impacts our everyday lives. Parliamentary discourse is motivated by a wide range of communicative roles and reveals political, ideological and institutional patterns, which is why it has always been of interest to scholars from a range of disciplines in the humanities and social science. Parliamentary proceedings are being increasingly made available in a digitized form, and turned into structured linguistic resources called corpora for many languages. Researchers use them to perform diverse linguistic, stylistic, cultural, societal and political studies.
2This tutorial shows the potential of richly annotated parliamentary corpora for research of the socio-cultural context and changes over time that are reflected through language use. The tutorial encourages students and scholars from digital humanities and social sciences who are interested in the study of socio-cultural phenomena through language, to engage with user-friendly digital tools for the analysis of large text collections. The tutorial is designed in a way that takes full advantage of both linguistic annotations and the available speaker and text metadata to formulate powerful quantitative queries that are then further extended with manual qualitative analysis in order to ensure adequate framing and interpretation of the results.
3The tutorial demonstrates the potential of the siParl 2.0 corpus which contains parliamentary debates of the National Assembly of the Republic of Slovenia from 1990 to 2018 via concordancers without the need for programming skills. No prior experience in using language corpora and corpus querying tools is required in order to follow this tutorial.
4This tutorial starts with a brief introduction to corpora and corpus analysis, followed by an introduction of the characteristics of specialized corpora of parliamentary debates and an overview of research into language and gender. The second part of the tutorial is hands-on and demonstrates the potential of some of the best-known corpus analysis techniques, such as concordances, frequency lists, keywords and collocations, to explore the topics female MPs debate in in the Slovenian Parliament over time and to compare and contrast their language use with that of their male counterparts.
* * Izr. prof., Filozofska fakulteta Univerze v Ljubljani, Inštitut za novejšo zgodovino in Institut Jožef Stefan; darja.fiser@ff.uni-lj.si
** **Asist., Filozofska fakulteta Univerze v Ljubljani, Aškerčeva 2, SI-1000 Ljubljana; Kristina.PahordeMaiti@ff.uni-lj.si
1. Avtorica naslovne izjave z redne seje 4. 6. 2003 je Cvetka Zalokar Oražem (LDS). Gl. Iskanje, pridobljeno 19. 2. 2021, http://hdl.handle.net/11346/siparl-NYUL.
2. Cornelia Ilie, »Parliamentary Debates,« v: Ruth Wodak in Bernhard Forchtner, ur., The Routledge Handbook of Language and Politics (London: Routledge, 2017), 309–25.
3. Łucja Biel, Agnieszka Biernacka in Anna Jopek-Bosiacka, »Collocations of Terms in EU Competition Law: A Corpus Analysis of EU English Collocations,« v: Language and Law (Cham: Springer, 2018), 249–74. Sylvia Jaworska in Kath Ryan, »Gender and the Language of Pain in Chronic and Terminal Illness: A Corpus-based Discourse Analysis of Patients’ Narratives,« Social Science & Medicine 215 (2018): 107–14.
4. Douglas Biber in Randi Reppen, The Cambridge Handbook of English Corpus Linguistics (Cambridge: Cambridge University Press, 2015). Tony McEnery in Andrew Hardie, Corpus Linguistics: Method, Theory and Practice (Cambridge: Cambridge University Press, 2011).
5. Paul Baker, Using Corpora to Analyze Gender (London: Bloomsbury, 2014).
6. Slovenian parliamentary corpus (1990-2018) siParl 2.0, pridobljeno 18. 2. 2021, http://hdl.handle.net/11356/1300.
7. NoSketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/4exc2b3e.
8. Google Preglednice – brezplačno ustvarjajte in urejajte preglednice v spletu, pridobljeno 18. 2. 2021, https://tinyurl.com/8mdwez3m.
9. Microsoft Excel, Spreadsheet Software, Excel Free Trial, pridobljeno 18. 2. 2021, https://tinyurl.com/6sdr9vwj.
10. NoSketch Engine @ CLARIN.SI, pridobljeno 18. 2. 2021, https://www.clarin.si/noske.
11. Konkordance – Obrazec za prvo poizvedbo, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-XOZH.
12. CLARIN.SI; Slovenska raziskovalna infrastruktura za jezikovne vire in tehnologije, pridobljeno 18. 2. 2021, https://tinyurl.com/wuhvy98b.
13. CLARIN – European Research Infrastructure for Language Resources and Technology | CLARIN ERIC, pridobljeno 18. 2. 2021, https://www.clarin.eu.
14. Slovenian parliamentary corpus (1990-2018) siParl 2.0 , pridobljeno 18. 2. 2021, http://hdl.handle.net/11356/1300.
15. Corpus Analysis with Antconc, pridobljeno 18. 2. 2021, https://tinyurl.com/3x85dvvs.
16. Basic Text Processing in R, pridobljeno 18. 2. 2021, https://tinyurl.com/f3nj4jt8.
17. Voices of the Parliament, pridobljeno 18. 2. 2021, https://tinyurl.com/hb68794d.
18. Slovenian parliamentary corpus (1990-2018) siParl 2.0 , pridobljeno 18. 2. 2021, http://hdl.handle.net/11356/1236.
19. Besedilni korpus – Wikipedija, prosta enciklopedija, pridobljeno 18. 2. 2021, https://tinyurl.com/23zu8r2e.
20. XML Tutorial, pridobljeno 18. 2. 2021, https://www.w3schools.com/xml.
21. TEI: Text Encoding Initiative, pridobljeno 18. 2. 2021, https://tei-c.org.
22. Token | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/48a5j4ru.
23. Lematizacija – Wikipedija, prosta enciklopedija, pridobljeno 18. 2. 2021, https://tinyurl.com/u37yyhur.
24. Corpus Linguistics: Method, theory and practice, pridobljeno 18. 2. 2021, https://tinyurl.com/27ajek5j.
25. Concordancers, pridobljeno 18. 2. 2021, https://tinyurl.com/yn6wcebj.
26. Laurence Anthony's AntConc, pridobljeno 18. 2. 2021, https://tinyurl.com/3ntaevtt.
27. WordSmith Tools home page, pridobljeno 19. 2. 2021, https://tinyurl.com/4256exts.
28. English Corpora: most widely used online corpora. Billions of words of data: free online access, pridobljeno 18. 2. 2021, https://www.english-corpora.org.
29. CQL – Corpus Query Language | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/skdvt638.
30. Concordance – most powerful corpus search | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/8zrs9f8n.
31. Wordlists – word frequency lists | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/9cn4afkz.
32. Keywords and term extraction | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/9sfrjfp3.
33. collocation | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/3ket5dps.
34. Quick Start Guide - learn to use | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/3hx8y7px.
35. Corpus Linguistics Analysis - Online Course – FutureLearn, pridobljeno 18. 2. 2021, https://tinyurl.com/4x9cp5t4.
36. The Danish Parliament Corpus 2009 - 2017, v1 , pridobljeno 18. 2. 2021, http://hdl.handle.net/20.500.12115/8.
37. Czech Parliament Meetings, pridobljeno 18. 2. 2021, http://hdl.handle.net/11858/00-097C-0000-0005-CF9C-4.
38. Synchrony and diachrony – Wikipedia, pridobljeno 18. 2. 2021, https://tinyurl.com/s96f8r38.
39. Metapodatek – Wikipedija, prosta enciklopedija, pridobljeno 18. 2. 2021, https://tinyurl.com/yyj88wak.
40. Pertti Alasuutari, Marjaana Rautalin in Jukka Tyrkkö, »The Rise of the Idea of Model in Policymaking: The Case of the British Parliament, 1803-2005,« European Journal of Sociology/Archives Européennes de Sociologie 59, št. 3 (2018): 341–63. Jane Demmen, Lesley Jeffries in Brian Walker, »Charting the Semantics of Labour Relations in House of Commons Debates Spanning Two Hundred Years,« Doing Politics: Discursivity, Performativity and Mediation in Political Discourse 80 (2018): 81.
41. Poslovnik državnega zbora, pridobljeno 18. 2. 2021, https://tinyurl.com/wmbczcj4.
42. Cornelia Ilie, »Parliamentary Debates.«
43. Diskurz – Wikipedija, prosta enciklopedija, pridobljeno 18. 2. 2021, https://tinyurl.com/tjj76yh.
44. Transcription (linguistics) – Wikipedia, pridobljeno 18. 2. 2021, https://tinyurl.com/e86cheyh.
45. Sandra Mollin, »The Hansard Hazard: Gauging the Accuracy of British Parliamentary Transcripts,« Corpora 2, št. 2 (2007): 187–210.
46. Kathryn Rix, »‘Whatever Passed in Parliament Ought to be Communicated to the Public’: Reporting the Proceedings of the Reformed Commons, 1833–50,« Parliamentary History 33, št. 3 (2014): 453–74.
47. Anja Bah Žibert – Wikipedija, prosta enciklopedija, pridobljeno 18. 2. 2021, https://tinyurl.com/ed7p75r8.
48. Sejni zapisi Državnega zbora, 33. seja (Ljubljana: Državni zbor, 20218), 128, dostopno na https://tinyurl.com/2s6r3r54
49. 33. redna seja Državnega zbora, 4. del, pridobljeno 18. 2. 2021, https://tinyurl.com/55twvm6u.
50. Corpus of Historical Low German HeliPaD User Manual, pridobljeno 18. 2. 2021, http://www.chlg.ac.uk/helipad.
51. Corpus of British Parliament speeches (Hansard), pridobljeno 18. 2. 2021, https://www.english-corpora.org/hansard.
52. Croatian parliamentary corpus ParlaMeter-hr 1.0 , pridobljeno 18. 2. 2021, http://hdl.handle.net/11356/1209.
53. Working with parliamentary corpora; Parthenos training, pridobljeno 18. 2. 2021, https://tinyurl.com/yypffemm.
54. Penelope Eckert in Sally McConnell-Ginet, Language and Gender (Cambridge: Cambridge University Press, 2013). Ruth Wodak, »Pragmatics and Critical Discourse Analysis: A Cross-disciplinary Inquiry,« Pragmatics & Cognition, 15 (2017): 203–25.
55. Matthew L. Newman, Clara J. Groom, Lori D. Handelman in James W. Pennebaker, »Gender Differences in Language Use: An Analysis of 14,000 Text Samples,« Discourse Processes 45, št. 3 (2008): 211–36.
56. Catherine Marshall, »Policy Discourse Analysis: Negotiating Gender Equity,« Journal of Education Policy 15, št. 2 (2000): 125–56.
57. Milica Antić Gaber in Gabriella Ilonszki, Women in Parliamentary Politics: Hungarian and Slovene Cases Comparur (Ljubljana: Peace Institute, Institute for Contemporary Social and Political Studies, 2003). Monique Leijenaar, How to Create a Gender Balance in Political Decision-making: A Guide to Implementing Policies for Increasing the Participation of Women in Political Decision-making (Luxembourg: Office for Official Publications of the European Communities, 1997). Christina Wolbrecht, »Female Legislators and the Women’s Rights Agenda: From Feminine Mystique to Feminist Era,« v: Cindy S. Rosenthal, ur., Women Transforming Congress (Norman: University of Oklahoma Press, 2002), 170–97.
58. Luke Blaxill in Kaspar Beelen, »A Feminized Language of Democracy? The Representation of Women at Westminster since 1945,« Twentieth Century British History 27, št. 3, 412–49.
59. Gl. Tracey L. Osborn, How Women Represent Women: Political parties, gender and representation in the state legislatures (Oxford: Oxford University Press, 2012).
60. Hanna Bäck, Marc Debus in Jochen Müller, »Who Takes the Parliamentary Floor? The Role of Gender in Speech-making in the Swedish Riksdag,« Political Research Quarterly 67, št. 3, 504–18.
61. Dorte H. Hansen, Costanza Navarretta in Lene Offersgaard, »A Pilot Gender Study of the Danish Parliament Corpus,« v: Darja Fišer, Maria Eskevich in Franciska de Jong, ur., Proceedings of the Eleventh International Conference on Language Resources and Evaluation (Miyazaki: LREC, 2018).
62. Eric O. Mensah in Sandra F. Wood, »Articulations of Feminine Voices in Ghana’s Parliament: A Study of the Hansard from 2010-2011,« AFRREV LALIGENS: An International Journal of Language, Literature and Gender Studies 7, št. 2 (2018): 61–77.
63. Lena Wängneru, »Intressen kontra stereotyper. Varför finns det kvinnliga och manliga politikområden i riksdagen?,« Statsvetenskaplig Tidskrift 99, št. 2 (1996).
64. Jennifer Coates, Women, Men and Language: A Sociolinguistic Sccount of Gender Differences in Language (London: Longman, 1997). Lia Litosseliti, Gender and Language: Theory and Practice (London: Hodder Arnold, 2006).
65. Janet M. Bing in Victoria L. Bergvall, »The Question of Questions: Beyond Binary Thinking,« v: Jennifer Coates, ur., Language and Gender: A Reader: Vol. 1 (Oxford: Blackwell, 1998), 496–510.
66. Blaxill in Beelen, »A Feminized Language of Democracy?«.
67. Angela Goddard in Lindsey M. Patterson, Language and Gender (London: Routledge, 2015).
68. Slovenian Parliamentary Corpus (1990-2018) siParl 2.0, pridobljeno 18. 2. 2021, http://hdl.handle.net/11356/1300, gl. Andrej Pančur, Tomaž Erjavec, Mihael Ojsteršek, Mojca Šorn in Neja Blaj Hribar, Slovenian Parliamentary Corpus (1990-2018) siParl 2.0.Slovenian language resource repository CLARIN.SI, 2020.
69. Državni zbor Republike Slovenije - Wikipedija, prosta enciklopedija, pridobljeno 18. 2. 2021, https://tinyurl.com/8ke5j554.
70. Named entity – Wikipedia, pridobljeno 18. 2. 2021, https://tinyurl.com/3jc7ftsd.
71. Corpus info: siParl 2.0 (parlament 1990-2018) , pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-0LBP.
72. Slovensko različico konkordančnika izberete v zgornjem desnem kotu s klikom simbola zobnika in izbiro ustreznega jezika s spustnega seznama.
73. Zaradi izida nove različice konkordančnika je ta trenutno zgolj delno preveden v slovenščino.
74. Portal DZ - Poslanske skupine, pridobljeno 18. 2. 2021, https://tinyurl.com/yh6brs32.
75. Milica Antić Gaber in Irena Selišnik, »The Slovene Version of a 'Fast Track' to Political Equality,« Teorija in Praksa 54, št. 2 (2017): 337.
76. Delež temelji na uradnem številu vseh poslank, kot ga navaja Simona K. Lipicer (2017), nato pa je deljen s številom vseh poslank in poslancev (tj. 90). Ta delež je rahlo višji od deleža, navedenega v naši analizi, v kateri smo dosledno uporabljali le podatke iz korpusa. Ker le redko vsi izvoljeni poslanci in poslanke ostanejo na istem položaju celoten mandat, jih nato zamenjajo drugi poslanci oziroma poslanke. To se odraža v korpusu, ki vključuje vse poslanke in poslance, in ne le tistih, ki so bili izvoljeni na volitvah. Glede na podatke iz korpusa je skupno število poslancev in poslank na mandat tako večje od 90.
77. European Institute for Gender Equality Home, pridobljeno 18. 2. 2021, https://tinyurl.com/84embf66.
78. Pri oznakah v korpusu je uporabljen generični moški spol.
79. Socialistična republika Slovenija - Wikipedija, prosta enciklopedija, pridobljeno 18. 2. 2021, https://tinyurl.com/k3mafd47.
80. Subcorpus information, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-KGFY.
81. Ker je to gradivo na voljo v slovenščini in angleščini, so poimenovanja podkorpusov v konkordančniku dvojezična. Vendar pa v tem gradivu zaradi jasnosti in jedrnatosti uporabljamo zgolj slovenski del imena podkorpusov. Povezava do angleških videov:
https://youtube.com/playlist?list=PLhZ_k72iCcmon0HVgd4O3UcwRIs-W-R0R.
82. Wordlists – word frequency lists | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/v4ta5zbh.
83. Word list, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-WR9T.
84. Word list, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-GSW5.
85. Zaradi napake v metapodatkih korpusa, ki so bili pripisani enemu od poslancev (in sicer poslancu z imenom Geza, ki mu je bil napačno samodejno pripisan ženski spol najverjetneje zaradi kombinacije končnice –a, ki je sicer tipična za samostalnike ženskega spola, in redkosti imena), podatki za šesti mandat v času analize ne odražajo uradnega števila poslank, ki je po navedbah Simone K. Lipicer (2017) 39, in ne 38, kot prikazuje korpus.
86. Antić Gaber in Selišnik, »The Slovene Version of a 'Fast Track',« 337.
87. Ibid.
88. Gl. Federico Nanni, Mahmoud Osman, Yi-Ru Cheng, Simone Paolo Ponzetto in Laura Dietz, »UKParl: A Semantified and Topically Organized Corpus of Political Speeches,« v: Darja Fišer, Maria Eskevich in Franciska de Jong, ur., Proceedings of the Eleventh International Conference on Language Resources and Evaluation (Miyazaki: LREC 2018).
89. Mladen Karan, Jan Šnajder, Daniela Širinić in Goran Glavaš, »Analysis of Policy Agendas: Lessons Learned from Automatic Topic Classification of Croatian Political Texts,« Proceedings of the 10th SIGHUM Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities (2016): 12–21.
90. Keyword (linguistics) – Wikipedia, pridobljeno 18. 2. 2021, https://tinyurl.com/3eu8u66s.
91. Word list, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-VBX5.
92. Word list, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-74HT.
93. Word list, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-AZM0.
94. Word list, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-7E3V.
95. Konkordančnik NoSketchEngine za računanje ključnih besed uporablja formulo Simple Maths.
96. Concordance – most powerful corpus search | Sketch Engine, pridobljeno 18. 2. 2021, https://tinyurl.com/8zrs9f8n.
97. Iskanje, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-VZB9.
98. Ministrstva | GOV.SI, pridobljeno 18. 2. 2021, https://tinyurl.com/jbjhnjjb.
99. Jennifer Coates, Women, Men and Language.
100. Cornelia Ilie, »Gendering Confrontational Rhetoric: Discursive Disorder in the British and Swedish Parliaments,« Democratization 20, št. 3(2013): 501–21.
101. Blaxill in Beelen, "A Feminized Language of Democracy?"
102. Bäck, Debus in Müller, »Who Takes the Parliamentary Floor?«
103. Antić Gaber in Ilonszki, Women in Parliamentary Politics.
104. Gl. Tracey L. Osborn, How Women Represent Women: Political Parties, Gender and Representation in the State Legislatures (Oxford: Oxford University Press, 2012).
105. Normalizing word counts – The Grammar lab, pridobljeno 18. 2. 2021, https://tinyurl.com/pkwaaf34.
106. Iskanje, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-YMFX.
107. Kolokacija – Wikipedija, prosta enciklopedija, pridobljeno 18. 2. 2021, https://tinyurl.com/5b87rmft.
108. logDice | Sketch Engine, pridobljeno, 18. 2. 2021, https://tinyurl.com/3dv63nhm.
109. Collocations, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-QIKC.
110. Collocations, pridobljeno 18. 2. 2021, http://hdl.handle.net/11346/siparl-Q5MN.
111. Kategorija skupno, kot nakazuje njeno ime, združuje kolokacijske kandidate, ki se pojavijo tako na seznamu za podkorpus govorov poslank kot za podkorpus govorov poslancev.
112. Antić Gaber in Ilonszki, Women in Parliamentary Politics.
113. Coates, Women, Men and Language.
114. Cate Poynton, Language and Gender: Making the Difference (Oxford: Oxford University Press, 1989).
115. Newman, Groom, Handelman in Pennebaker, "Gender Differences in Language Use."
116. Resource families | CLARIN ERIC, pridobljeno 18. 2. 2021, https://www.clarin.eu/resource-families.